Introduction
Welcome to the SUS Language documentation. The chapters under "Intro To SUS" will introduce you to the main features of the language, but if you'd like to skip to the core selling point of SUS, then you can head straight to Latency Counting.
Some libraries we maintain here at PC2 might be of use to you:
- SUS Standard Library
- sus-float: Xilinx floating point IP wrappers
- sus-xrt: AXI masters & slaves for working with XRT
- sus-xpm: SUS wrappers for Xilinx Parametrized Macros. (RAMs, FIFOs, etc)
Installation
Installation is done through Rust's package manager cargo (cargo installation info). 1
cargo install sus_compiler
By default, the standard library is stored in the $XDG_DATA_HOME folder, but it can be overwritten with INSTALL_SUS_HOME=/path/to/sus_home/ cargo install sus_compiler.
Supported Editors
- VSCode: SUS Hardware Design Language (source: (sus-lsp))
- VIM: papeg/sus.vim. It supports vim and neovim and brings in syntax highlighting and lsp support. For vim it depends on prabirshrestha/vim-lsp. Install with your favorite plugin manager, like vim-plug:
call plug#begin()
if !has('nvim')
Plug 'prabirshrestha/vim-lsp'
endif
Plug 'papeg/sus.vim'
call plug#end()
Useful Libraries
Some libraries we maintain here at PC2 might be of use to you:
- sus-float: Xilinx floating point IP wrappers
- sus-xrt: AXI masters & slaves for working with XRT
- sus-xpm: SUS wrappers for Xilinx Parametrized Macros. (RAMs, FIFOs, etc)
Your first module
Since doing a "Hello World" in hardware isn't really viable (What's a "string"? Do I pass 'H', 'e', ... over the serial port?), we instead create a simple OR gate.
In the module below, we first declare two inputs and an output, and finally do a continuous assignment c = a | b. It synthesizes to a simple OR gate.
Create a file hello_hardware.sus and add the following code to it:
module hello_hardware {
input bool a
input bool b
output bool c
c = a | b
}

You can then compile this file with sus_compiler hello_hardware.sus --top hello_hardware -o codegen.sv. It will compile hello_hardware as top module, and the resulting code is stored in codegen.sv.
The generated systemverilog:
// THIS IS A GENERATED FILE (Generated at 2026-02-14T16:36:01+01:00)
// This file was generated with SUS Compiler 0.3.7
// hello_hardware #()
module hello_hardware(
input clk,
input wire a,
input wire b,
output /*mux_wire*/ logic c
);
wire _3;
assign _3 = a | b;
always_comb begin // combinatorial c
// Combinatorial wires are not defined when not valid.
// This is just so that the synthesis tool doesn't generate latches
c = 1'bx;
c = _3;
// PATCH Vivado 23.1 Simulator Bug: 1-bit Conditional Assigns become don't care
c = c;
end
endmodule
This generated code can then be synthesized or simulated using a tool of your choice. Since at PC2 we're using the u280 and v80 FPGAs, we tend to use Vivado's TODO xsim.
Conditionals
SUS includes two kinds of conditionals: Compiletime conditionals, denoted by if, and Runtime conditionals, denoted by when.
Compiletime (if) conditionals are executed at instantiation time. The SUS interpreter takes either branch depending on the value of the condition. (See How SUS is Compiled and Compile-Time Code)
Runtime (when) conditionals synthesize to "guards" on any runtime assignments within them.
If Example:
module CompileTime {
gen int SIZE = 20
gen int ALIGN
if SIZE <= 16 {
ALIGN = 2
} else if SIZE <= 32 { // if statements can be chained
ALIGN = 4
} else {
ALIGN = 8
}
// Here ALIGN=4 ...
}
When Example:
module Abs {
input int#(FROM: -20, TO: 21) x
output int y
when x < 0 {
y = -x
} else {
y = x
}
}
Boolean Operators
The boolean "and" &, "or" |, and "xor" ^ operators are used to chain multiple comparisons. The "not" ! operator inverts. SUS does not does not support the "double" boolean operators (&&, ||) that are common in SystemVerilog and other languages1. As explained in Operator Precedence, the boolean operators have lower precedence than the comparison operators, as shown in the following example below. This is a slight difference to other languages.
1 The reason SystemVerilog, C and others provide this operator is to do an implicit conversion of the boolean vector type to a single boolean. In SUS this kind of reduction is better expressed with the unary | and & operators. See Tensor Reductions.
module Between {
input int#(FROM: 0, TO: 256) min
input int#(FROM: 0, TO: 256) max
input int#(FROM: 0, TO: 256) v
output bool is_between
when min <= x & x >= max {
is_between = true
} else {
is_between = false
}
}
Compile-Time Code
To make metaprogramming easier, SUS comes with some control flow constructs that make building repetitive structures easier.
The way it works is that when a module is instantiated (IE, concrete values for its parameters are known), the statements in the module body are executed one by one. Control flow constructs like if, for and while affect the control flow during instantiation, but are no longer present in the generated hardware. When execution passes over compile-time (called "generative" (gen) code), it updates the current state. This usually is setting the variable of a gen variable. When a non-generative statement is executed, the compiler instead instantiates the wire, register, or submodule. For more information see How SUS is compiled.
if
(For the comparison to the runtime equivalent when, see Conditionals).
When executing an if statement, the compiler checks if the (compile-time) condition is true. If so, the contents of the if statement are included in the resulting hardware. If false, they aren't.
As an example, let's say we want to implement a shift register. For small depths, we would instantiate several registers back to back. But if the the depth becomes larger, the cost of all those registers would make us want to use a memory block instead.
module ShiftReg#(T, int DEPTH) {
input T din
output T dout
if DEPTH <= 3 {
// Not worth it to use the memory block. A few registers back to back will do.
state T[DEPTH] regs
regs[0] = din
for int I in 1..DEPTH {
regs[I] = regs[I - 1]
}
dout = regs[DEPTH - 1]
} else {
// Create a memory block, with a rotating index
state T[DEPTH] mem
state int#(FROM: 0, TO: DEPTH) cur_idx
initial cur_idx = 0
cur_idx = cur_idx + 1 mod DEPTH
dout = mem[cur_idx]
}
}
for
For loops express repeated structures. As the loop iterates, it repeatedly executes the body with incrementing index values, starting at the lower bound, and incrementing by one until reaching the upper bound. Note that the lower bound is the first index in the iteration, whereas the last index in the iteration is upper_bound - 1. Inclusive lower bound, exclusive upper bound. As of the time of writing, for loops do not support step size other than '1'.
module Sums {
input int#(FROM: 0, TO: 16)[4] as
input int#(FROM: 0, TO: 16)[4] bs
output int[10] rs
for int I in 0..4 {
rs[I] = as[I] + bs[I]
}
/*
The above loop is equivalent to writing:
rs[0] = as[0] + bs[0]
rs[1] = as[1] + bs[1]
rs[2] = as[2] + bs[2]
rs[3] = as[3] + bs[3]
*/
}
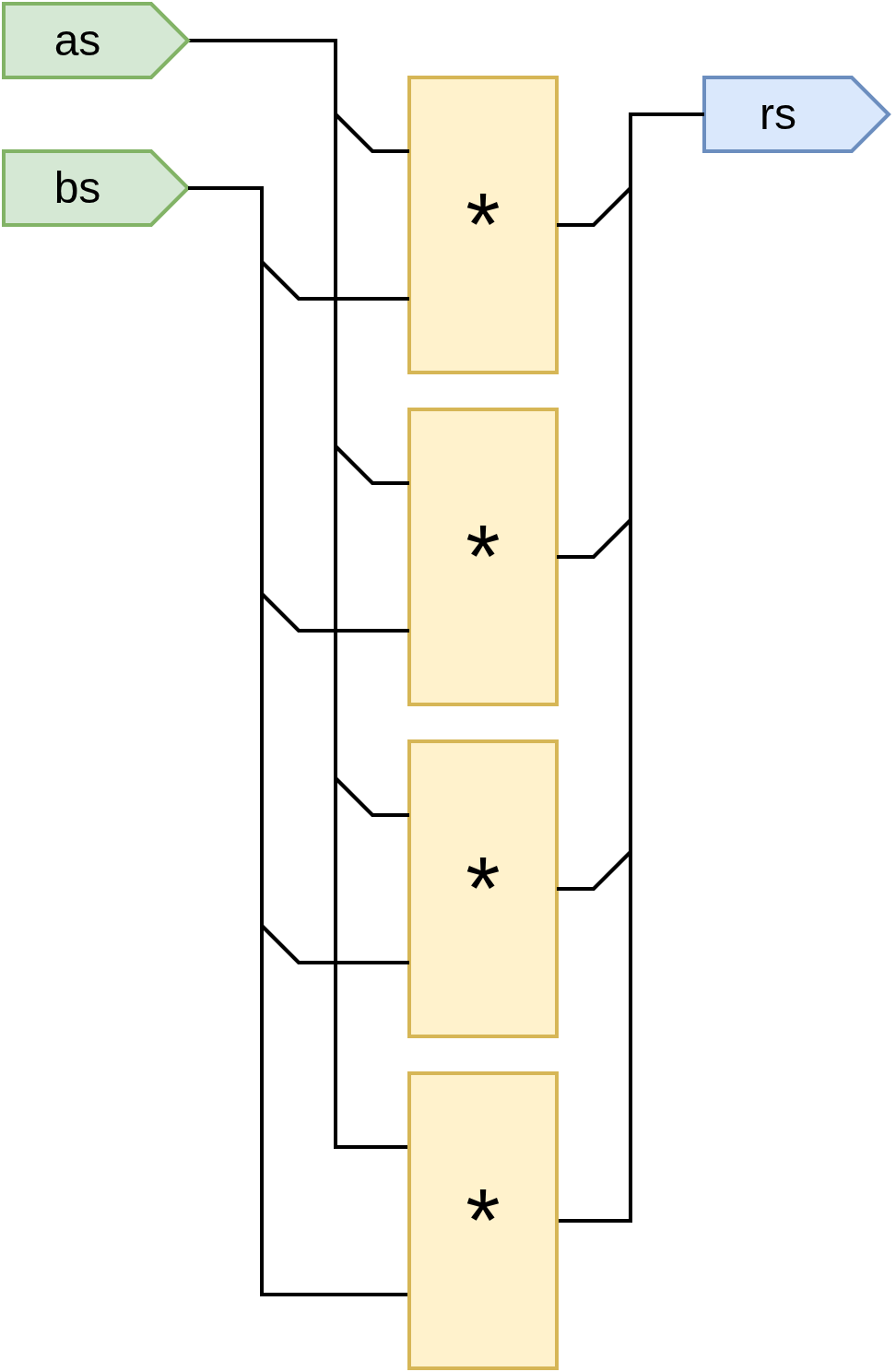
while
Not yet implemented.
Larger example
As an example, say we wish to implement the typical Fizz Buzz interview question problem. We are given a number, if it's divisible by 3, output "fizz", when divisible by 5 "buzz", and "fizzbuzz" when divisible by both. Otherwise, the input number itself should be returned. We can do a direct implementation of it as shown below:
module fizz_buzz {
input int#(FROM: 0, TO: 1000) v
output int fb
gen int FIZZ = 888
gen int BUZZ = 555
gen int FIZZ_BUZZ = 888555
bool is_fizz = v mod 3 == 0
bool is_buzz = v mod 5 == 0
when is_fizz & is_buzz {
fb = FIZZ_BUZZ
} else when is_fizz {
fb = FIZZ
} else when is_buzz {
fb = BUZZ
} else {
fb = v
}
}

Although this would be an adequate solution for hardware simulation, divide and modulo blocks are rarely synthesizeable. For those, we may want to reach for a precomputed lookup table instead. Indeed, we can declare the lookup table as a compile-time array, and fill it out with all possible inputs we might encounter with a for loop. Note that since this is compiletime, the when blocks from before have turned into if statements.
module fizz_buzz_gen {
gen int TABLE_SIZE = 1000
input int#(FROM: 0, TO: TABLE_SIZE) v
output int fb
gen int FIZZ = 888
gen int BUZZ = 555
gen int FIZZ_BUZZ = 888555
gen int[TABLE_SIZE] LUT
for int I in 0..TABLE_SIZE {
gen bool IS_FIZZ = I mod 3 == 0
gen bool IS_BUZZ = I mod 5 == 0
if IS_FIZZ & IS_BUZZ {
LUT[I] = FIZZ_BUZZ
} else if IS_FIZZ {
LUT[I] = FIZZ
} else if IS_BUZZ {
LUT[I] = BUZZ
} else {
LUT[I] = I
}
}
// The only line that actually generates hardware
fb = LUT[v]
}
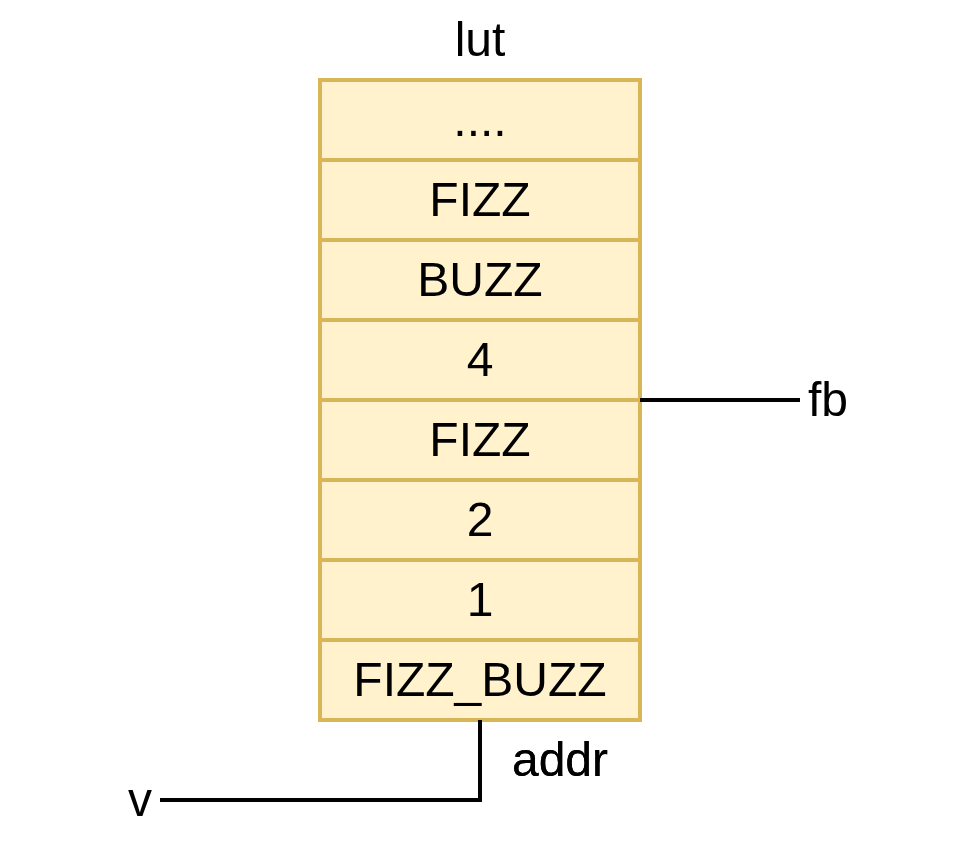
Bounded Integers
type int#(int FROM, int TO)
In SUS, integers are bounded. They are described with an inclusive lower FROM bound, and an exclusive upper TO bound. These bounds are compile-time values that can be positive or negative. Compile-Time integer values themselves are unbounded and can be arbitrarily large. (They are stored as Big Integers internally).
int#(FROM: 0, TO: 16) four_bit_int
int#(FROM: 0, TO: pow2#(E: 32)) u32 // unsigned 32-bit int
int#(FROM: 0, TO: pow2#(E: 64)) u64 // unsigned 64-bit int
int#(FROM: -pow2#(E: 31), TO: pow2#(E: 31)) i32 // signed 32-bit int
int#(FROM: -pow2#(E: 63), TO: pow2#(E: 63)) i64 // signed 64-bit int
int#(FROM: 7, TO: 8) seven = 7
int#(FROM: -3, TO: -2) minus_three = -3
// In many cases, integer bounds can be inferred
int five_bit_int = four_bit_int + seven
// infers to int#(FROM: 7, TO: 23)
By defining integers as bounded instead of explicitly signed or unsigned at a given bitwidth, we sidestep many of the common pitfalls that plague integer operations in other HDLs, such as unexpected truncation if we used too few bits for the result of an operation, or Verilog's odd automatic coersion of signed values to unsigned if the other operand is unsigned. As an added benefit, these bounds let us perform compile-time boundschecks on any arrays we may want to index, as well as letting us define the interfaces of our modules more precisely.
After compilation, bounded integers do map to bitvectors, with the mapping to unsigned bitvectors for FROM >= 0, and signed bitvectors if FROM < 0. The size of these bitvectors is the minimum number of bits required to hold all the values in the range of the integer. For unsigned integers, this is simply clog2#(V: TO). One could argue that for large integers with narrow bounds (such as int#(FROM: 20, TO: 25)) a narrower bitwidth could be used, but this would be confusing for anyone viewing such wires under a simulator.
gen int INT_TO = 20
sizeof#(T: type int#(FROM: 0, TO: INT_TO)) == clog2#(V: INT_TO)
Operators
Integers support the following operators:
+signed/unsigned addition-signed/unsigned subtraction*signed/unsigned multiply/signed/unsigned divide%signed/unsigned remaindermodsigned/unsigned modulo<<arithmetic or logical left shift, depending on signedness>>arithmetic or logical right shift, depending on signednessunary -signed/unsigned negation
The mod operator is recommended for integer modulos, since it has a more widely useful behavior over negative integers compared to %. Also, to support the common pattern of implicit 2s complement modular overflow, mod has a prescedence below the common arithmetic operators:
gen int SIZE = 200
state int#(FROM: 0, TO: 200) cur_index
input bool up
when up {
// Note, no parentheses are needed
cur_index = cur_index + 1 mod SIZE
} else {
cur_index = cur_index - 1 mod SIZE
}
Guaranteed optimizations
The SUS code generator will take care to convert mod operators to more efficient bit masking or conditional assigns, if powers of two are involved, or if modulo-ing over small differences.
For each v, v mod N optimizations
int#(FROM: 0, TO: N+1) v: optimizes to conditional assign to 0int#(FROM: -1, TO: N) v: optimizes to conditional assign toNint#(FROM: 0, TO: 2*N) v: optimizes to conditional assign tov - Nint#(FROM: -N, TO: N) v: optimizes to conditional assign tov + Nany vwithNa positive power of 2: optimizes to a bitmask
What about bitwise operators?
Since there is no natural way to compute the bounds of an & or | operation on integers, the int type doesn't support these. For the most common operations one would want to use these for, IE masking out the lower N bits, or concatenating bits, SUS instead provides:
However, if you do need to apply boolean operators to your integers not covered by the above, or
- IntToBool
- BoolToInt
- IntToBits
- UIntToBits
- BitsToInt
- BitsToUInt It is recommended to use these instead of ToBits and FromBits, as they display the intent more clearly.
The compile-time equivalents of those: IntToBitsGen UIntToBitsGen BitsToIntGen BitsToUIntGen
Integer Narrowing
In most cases, the recommended way to narrow the bounds of an integer is to use mod with a power of 2. This mimics the rollover behavior seen in Verilog or VHDL. However, if you need narrowing to ranges that are not powers of 2, you can use IntNarrow as a fallback.
There are plans for introducing flow-sensitive integer narrowing, which should alleviate most of the circumstances where IntNarrow is needed, but at this time this isn't implementated yet.
Clocks
Similar to Domains, the clock statement affects all ports declared after it. If no clock is specified then a default clock named clk is used. When a clock is declared, it implicitly also declares a domain of the same name. When wires are connected, they are forced to be part of the same clock domain. This is how clock information travels from the ports to the internal wires and registers.
module MultiClock {
clock clka
input int value_a // is on clka
clock clkb
output int value_b // is on clkb
int another_wire = value_a // Is on clka due to being connected to value_a
// The following would result in an error, due to connecting clock domains `clka` and `clkb`
// value_b = another_wire
}
Clock Domain Crossings
At the time of writing, no explicit clock domain crossing primitives are provided in the SUS Standard Library. You can build them yourself using CrossDomain, or by wrapping primitives provided by your FPGA Vendor.
Output clocks
It is possible for a module to declare one or more output clocks. These are clocks which the module itself must generate. The SUS standard library has no such modules, so it only sees use if you wish to wrap PLLs with an ´extern module´.
extern module MyPLL {
clock in_clk
output clock out_clk
}
Ports
Ports in SUS are very similar to what you'd find in SystemVerilog, VHDL, and the like. There's the continuous input and output ports, and actions and triggers.
input and output
The input and output keywords are used to declare continuous ports. They are the most basic kind of port, with the same semantics as their SystemVerilog equivalents. We call them continuous because, in contrast to actions and triggers, they are meant to carry a valid value every cycle. They are declared with their respective keywords modifying a non-generative wire declaration. To access them from a parent module, read and write to them as if they were struct fields.
/// Declare the input and output ports
module BoolToInt {
input bool the_bool
output int as_int
when the_bool {
as_int = 1
} else {
as_int = 0
}
}
/// Usage
module UseBoolToInt {
BoolToInt instance
instance.the_bool = true
int result = instance.as_int
}
Where possible, it is recommended to try to use actions and triggers instead. Normally you wouldn't see them very often, except for in External Modules which may not be readily expressible using these more high-level constructs.
Actions and Triggers
More information on these is found in Actions, Triggers and Conditional Bindings
Actions, Triggers and Conditional Bindings
A very common pattern in hardware design is the coupling of data to a "valid" signal. Because it is so common, and there's no hardware overhead to implementing it, SUS provides a syntactic sugar for it named action and trigger.
An action can be thought of as a sort-of method on a submodule. It can take any number of inputs, and produce any number of outputs. When the action is "called", the effect is that the "valid" wire associated with the action (of the same name as the action itself) is set to "1". Important to know is that since an action still represents a physical connection on a module, it can only be used once per cycle. Don't try to call an action in a for-loop and expect it to be "executed" multiple times.
/// Declaration of Actions
module memory#(T, int DEPTH) {
T[DEPTH] mem
action write: int#(FROM: 0, TO: DEPTH) wr_addr, T wr_data {
mem[wr_addr] = wr_data
}
action read: int#(FROM: 0, TO: DEPTH) rd_addr -> T rd_data {
rd_data = mem[rd_addr]
}
}
/// Is equivalent to
module memory#(T, int DEPTH) {
T[DEPTH] mem
input bool write
input int#(FROM: 0, TO: DEPTH) wr_addr
input T wr_data
when write {
mem[wr_addr] = wr_data
}
input bool read
input int#(FROM: 0, TO: DEPTH) rd_addr
output T rd_data
when read {
rd_data = mem[rd_addr]
}
}
/// Calling of Actions
module use_memory {
memory#(T: type bool[20], DEPTH: 5) mem
state int cur_idx
// Really this should also be an action
bool do_read
output bool[20] dout
when do_read {
dout = mem.read(cur_idx) // <<<===
cur_idx = (cur_idx + 1) % 5
}
}
Triggers
Triggers are like reverse actions. In this case it is the submodule that wishes to invoke an action on its parent module, not dissimilar to a callback. In the case of triggers, it is the submodule itself that "calls" the trigger, thereby setting the trigger's "valid" bit to 1 as with actions.
/// Declaration of triggers
module iterator#(int MAX) {
state int cur
action start {
cur = 0
}
trigger iter : int v, bool last
when cur != MAX {
iter(cur, cur == MAX - 1)
cur = (cur + 1) % MAX
}
}
In the parent module, we can react to the submodule's trigger using a "conditional binding", marked with <<<===.
/// Use of triggers and conditional bindings
module use_iter {
int[6] terms = [5, 7, -9, 6, 5, 2]
state int total
iterator#(MAX: 6) iter
action sum_up {
total = 0
iter.start()
}
trigger done : int sum
when iter.iter : int idx, bool last { // <<<===
int new_total = (total + terms[idx]) % 256
when last {
done(new_total)
}
total = new_total
}
}
To recap
- An
actionis for the parent module to signal one of its submodules - A
triggeris for the submodule to signal its parent
Module Parameters
Modules, types and compile-time functions can have compile-time parameters. These can be value parameters, like 0, true, "hello", etc, or type parameters.
An example of such a declaration:
module FIFO#(T, int DEPTH, int MAY_PUSH_LATENCY) {
// ...
}
The parameters are given within the #() compile-time parameter brackets.
Type parameters are specified as simply their name, whereas Value parameters are their type, followed by their name. Note that because they are implicitly compile time, they do not need to be marked with gen.
To instantiate a module, type or compile-time function, apply the #() compile time parameter brackets to the module name:
FIFO#(T: type float, DEPTH: 256) my_fifo
// MAY_PUSH_LATENCY is inferred by Latency Counting
Type parameters must be passed as <type parameter name>: type <type expression>. The type keyword is required for the parser to understand what comes after it as a type. Value parameters are passed simply as <value parameter name>: <value>.
Parameters can also be passed with a shorthand of just the parameter name, if there is a local generative variable of the same name:
module Use_FIFO#(T) {
gen int DEPTH = 256
FIFO#(T, DEPTH) my_fifo
}
Parameters may also be omitted, and in that case they are inferred, either through regular type-based inference, or from Latency Inference if possible.
Parameter Inference
Module parameters are often inferrable from the types and latencies of the module's ports. Most Parameter inference happens via exact match. So for instance, if a type float[3] is provided to an input of of type T, then T infers to type float[3].
module IAmInferrable#(T) {
input T my_input
//...
}
module Use {
float[3] x = [0.1, 0.2, 0.3]
IAmInferrable inf // Infers to T: type float[3]
inf.my_input = x
}
Similarly, values used within the declaration of types can also be inferred. For instance, in the following case, the parameter WIDTH can be inferred from the size of the incoming boolean array.
module InferMyArraySize#(int WIDTH) {
input bool[WIDTH] bits
//...
}
module Use {
InferMyArraySize inf // Infers to WIDTH: 32
inf.bits = 32'hDEADBEEF
}
Integer Inference
While other parameters can only be inferred by exact match, integer parameters actually can be inferred more flexibly due to the integer subtyping relationship, with inference candidates providing minimum and maximum values rather than requiring an exact match.
For example, let's take this IntegerEquals module:
module IntegerEquals #(int FROM, int TO) {
action IntegerEquals :
int#(FROM: FROM, TO: TO) a,
int#(FROM: FROM, TO: TO) b ->
bool result
result = a == b
}
module UseIntegerEquals {
int#(FROM: 3, TO: 9) x
int#(FROM: -2, TO: 5) y
bool are_eq = IntegerEquals(x, y)
// infers to IntegerEquals#(FROM: -2, TO: 9)
}
On IntegerEquals::FROM, there are two maximum constraints: One for FROM <= 3 for a, and one for FROM <= -2 for b. Therefore FROM infers to -2. Likewise IntegerEquals::TO has two minimum constraints: TO >= 9 for a and TO >= 5 for b, inferring TO to 9.
Latency Inference
Latency Inference is a kind of integer inference. And as with inference of integer bounds, Latency Inference only applies a maximum latency constraint from an output to an input, which translates to a minimum or maximum bound on the latency inferrable parameter.
See Latency Inference.
Extern Modules
Extern modules are declared with the extern keyword. Their types must be fully specified, and absolute latencies must be provided on all ports.
Let's say we want to wrap the following SystemVerilog module. It is a floating point adder IP core, with free-flowing pipeline depth of 11 stages.
// Latency of 11 cycles
module fp32_add_ip (
input logic aclk,
input logic s_axis_a_tvalid,
input logic[31:0] s_axis_a_tdata,
input logic s_axis_b_tvalid,
input logic[31:0] s_axis_b_tdata,
output logic m_axis_result_tvalid,
output logic[31:0] m_axis_result_tdata
);
endmodule
We would wrap it like so:
extern module fp32_add_ip {
clock aclk
input bool s_axis_a_tvalid'0
input float s_axis_a_tdata'0
input bool s_axis_b_tvalid'0
input float s_axis_b_tdata'0
output bool m_axis_result_tvalid'11
output float m_axis_result_tdata'11
}
We've explicitly mapped the clock, and all ports at appropriate absolute latencies. If there are any integers or arrays within the module, they must be sized explicitly.
Type Mappings:
sus => systemverilog
bool x=>logic xfloat x=>logic[31:0] xdouble x=>logic[63:0] x- unsigned
int#(FROM: 0, TO: 256) x=>logic[0:$clog2(256)] x - signed
int#(FROM: -256, TO: 256) x=>signed logic[0:$clog2(512)] x - Arrays:
int#(FROM: 0, TO: 128)[5] x=>logic[0:$clog2(256)] x[0:4] - Except the lowest level of boolean array:
bool[5] x=>logic[4:0] x - Arrays of boolean arrays again become unpacked:
bool[5][20] x=>logic[4:0] x[0:19]
Parameters
You may wrap systemverilog modules with parameters. Simply copy over the parameter to SUS with an appropriate type:
The SystemVerilog Module:
module PopCount #(parameter integer SIZE) (
input clk,
input logic[SIZE-1:0] bits,
output logic[$clog2(SIZE+1)-1:0] count
);
endmodule
Maps to a SUS Extern Module:
extern module PopCount #(int SIZE) (
clock clk
input bool[SIZE] bits,
output int#(FROM: 0, TO: SIZE+1) count
);
endmodule
Latency Counting
If there's one thing the name "SUS" is synonimous with, it's Latency Counting. Latency Counting is the algorithm that makes it easy to add pipeline stages anywhere in a hardware design, automatically adjusts the pipelining of the signals around it, and even lets the various latency-sensitive modules in your design react to the change in latency.
A short video on how Latency Counting is used is here:
Theory
Inserting latency registers on every path that requires them is an incredibly tedious job. Especicially if one has many signals that have to be kept in sync for every latency register added. This is why I propose a terse pipelining notation. Simply add the reg keyword to any critical path and any paths running parallel to it will get latency added to compensate. This is accomplished by adding a 'latency' field to every path. Starting from an arbitrary starting point, all locals connected to it can then get an 'absolute' latency value, where locals dependent on multiple paths take the maximum latency of their source paths. From this we can then recompute the path latencies to be exact latencies, and add the necessary registers.
Automatic pipeline balancing
Imagine we wish to pipeline a "raise to the 17th power" module. We can implement this computation by multiplying i by itself 4 times, and then multiplying that by the original i once more. Now, because the critical path in this module is be quite long, we decide to add a few pipeline stages between the multipliers using the reg keyword, such that our critical path only ever includes two multipliers instead of 5. Latency Counting will then ensure that the parallel path (the original i copy), is delayed by the same amount by adding two registers on that path too.
module pow17 {
input int#(FROM: 0, TO: 10) i
output int o
int i2 = i * i
reg int i4 = i2 * i2
int i8 = i4 * i4
reg int i16 = i8 * i8
o = i16 * i
}
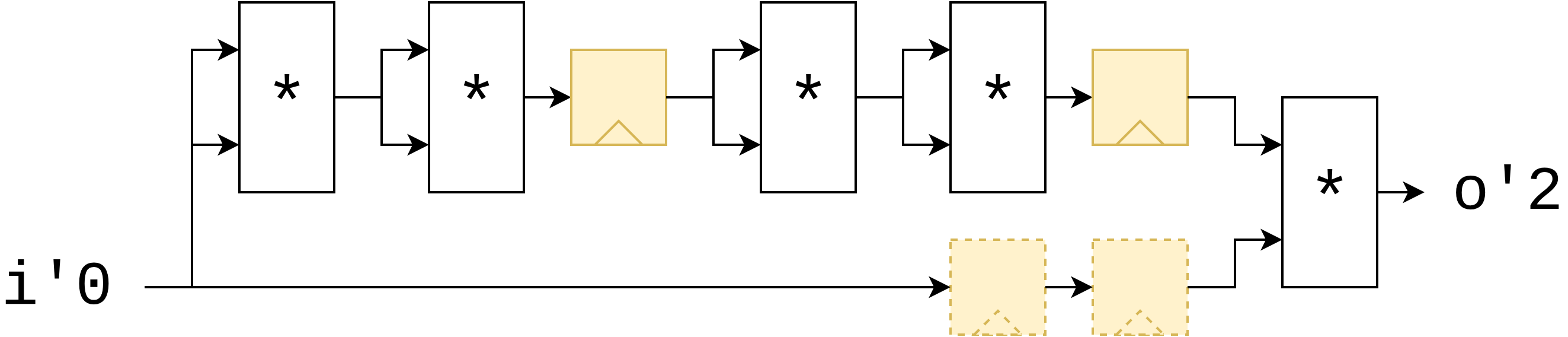
Inference of latencies on ports
Some languages that support pipelining constructs similar to this have the restriction that all inputs must be provided at the same time, and all outputs are produced at the same time, some number of clock cycles later. SUS does not have this restriction. The ports in a module will be assigned absolute latencies such that the inputs come in as late as possible, and the outputs are produced as early as possible, thereby packing the module together as compactly as possible. Using a module with such skewed port latencies may seem daunting and error-prone at first, but you'll notice that where this module is instantiated, the compiler will automatically adjust for its port latencies so you as the user don't have to worry about it.
module wonky_port_latencies {
input int#(FROM: 0, TO: 16)[4] factors
input int#(FROM: 0, TO: 16) add_to
input int#(FROM: 0, TO: 16) product
output int total
reg int mul0 = factors[0] * factors[1]
reg int mul1 = factors[2] * factors[3]
reg product = mul0 * mul1
reg total = product + add_to
}
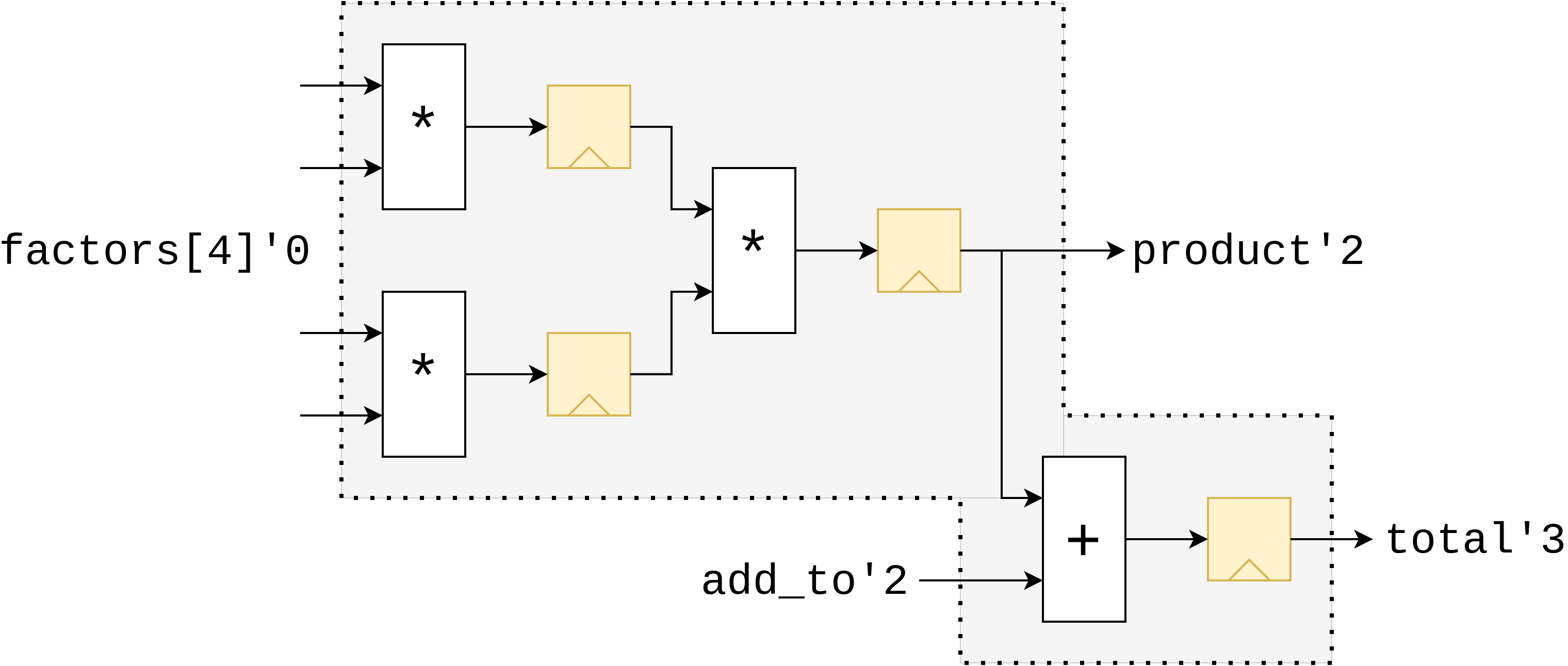
Latency Specifiers
The way Latency Counting actually works is by assigning an integer value to each wire in your design - the so-called "Absolute Latency" - which denotes how much this wire is delayed compared to an arbitrarily chosen starting point. The programmer can explicitly specify these absolute latencies by adding 'N annotations to the wire's declarations. This can cause the compiler to have to insert extra registers.
module module_taking_time {
input bool i'0
output bool o'5
o = i
}

Specifying latencies on ports is also the gateway to using Latency Inference.
Solution Uniqueness
A promise of SUS is that it's still an RTL language. This means that the code you write should have exactly one well-specified realization as a netlist. Remember the basic rules of Latency Counting:
reg and submodules require a minimum latency between their endpoints, but adding latency more registers is always allowedThese two rules still allow for an infinite number of valid solutions. (Simply push inputs backward and outputs forward.) To counteract this freedom, we can add the requirement: "inputs must be taken as late as possible, outputs must be provided as early as possible". This seems promising, but what "late" and "early" precisely mean is still a little vague. We can make it more concrete by reformulating it as:
With this requirement, the vast space of possible latency assignments is already mostly constrained, though we still have a little wiggle-room in where exactly we insert Latency Registers for balancing according to Rule 2. Finally, we constrain these too with:
Rule 4 did quite conspicuously leave out what to do with wires that are neither in the fanout of an input wire, nor in the fanin of an output wire. Sadly, I've not yet found a good rule to constrain such wires. Luckily it turns out that wires that are neither connected to an input, nor to an output have little practical use. Since they do not interfere with the important downstream benefits of Solution Uniqueness, it is seen as acceptable to simply leave their absolute latencies up to the implementation details of Latency Counting.
Note: It is allowed to shift all absolute latencies upwards or downwards by a fixed offset, since this does not change any of the differences between the ports. We only consider uniqueness of the absolute latencies up to a constant offset.
The benefits of Uniqueness
- The interface of a module is always deterministic. Module ports are always at a minimal distance from one another. If the compiler notices that the choice is not deterministic, it will throw an No Unique Port Latencies Error.
- The Interence of Submodule Parameters is fully deterministic.
- The placement of latency registers in wires that are in the fanin of output ports, and the fanout of input ports is intuitive and predictable, even if sometimes a little surprising.
Latency Inference
Besides computing the absolute latencies of all wires in a module based on the absolute latencies of all of its submodules ("Latency Counting"), it is also possible to infer the parameters of your submodules based on the latencies present on their ports, which we term "Latency Inference". For this, one or more parameters of your Latency Sensitive module must be inferrable.
Latency Inference starts at the declaration of your module. You must attach absolute latency annotations to at least an input and an output port of your module, and the difference between those absolute latencies must be linear in exactly one integer parameter of this module. Since this is a bit of a mouthful, let's look for example at FIFO:
module FIFO #(T, int DEPTH, int MAY_PUSH_LATENCY) {
domain push_dom
output bool may_push'-MAY_PUSH_LATENCY
action push'0 : T push_data'0
domain pop_dom
output bool may_pop'0
action pop'0 : -> T pop_data'1
}
As can be seen on FIFO's inference diagram. The green lines show that MAY_PUSH_LATENCY can be inferred from the paths from may_push to push, and may_push to push_data. Now, how precisely is this inference done?
For a very minimal example of inference, InferFIFO instantiates FIFO and a fp32_mul operator.
module InferFIFO {
FIFO#(DEPTH: 256) fifo
input float f
when fifo.may_push {
// fp32_mul has 8 cycles latency
float f_squared = fp32_mul(f, f)
fifo.push(f_squared)
}
}
So, in this example, there is a path from fifo.may_push, through activating the fp32_mul, to fifo.push_data. Initially, right after execution the module looks as below. Neither fifo, nor fp32_mul have been instantiated yet. fifo might attempt to do a Latency Inference for MAY_PUSH_LATENCY on that path, but since fp32_mul hasn't been instantiated yet, and therefore its latency isn't known yet, the inference attempt gets poisoned.

After one step of typechecking, the compiler has seen fp32_mul has no template parameters and thus instantiates it. From the instantiation, the compiler learns it has a latency of 8 clock cycles. This new information updates the Latency Counting graph, and importantly removes the poison edges and replaces them with "Latency 8" edges.
fifo makes a second attempt at Latency Inferring MAY_PUSH_LATENCY, and this time, inference succeeds. The search algorithm travels out from may_push, through the now known 8 cycle latency of fp32_mul, and returns to push_data with a measured distance of 8 cycles. From this, MAY_PUSH_LATENCY=8 is inferred.

With all of fifo's parameters now known, the compiler can also instantiate it.

Designing Latency Sensitive Interfaces
Fundamentally, making a module parameter Latency Inferrable isn't difficult. Simply make sure to annotate have at least one input port, and one output port in the same domain with Absolute Latencies. If the Absolute Latencies you specified are at an offset linear in that module parameter, then it'll be possible to infer the parameter from those ports1.
Caveat, the compiler is fairly lenient in the kinds of expressions can be in such inferrable annotations, but complex operations, like pow2, clog2, etc will prevent the compiler from inferring the linearity. It's best to keep such expressions simple. +, -, * all work, but nothing beyond those.
In its most basic form, a Latency Sensitive module looks like this:
module ThisModuleIsInferrable #(int V) {
output bool from'0
input bool to'V
}
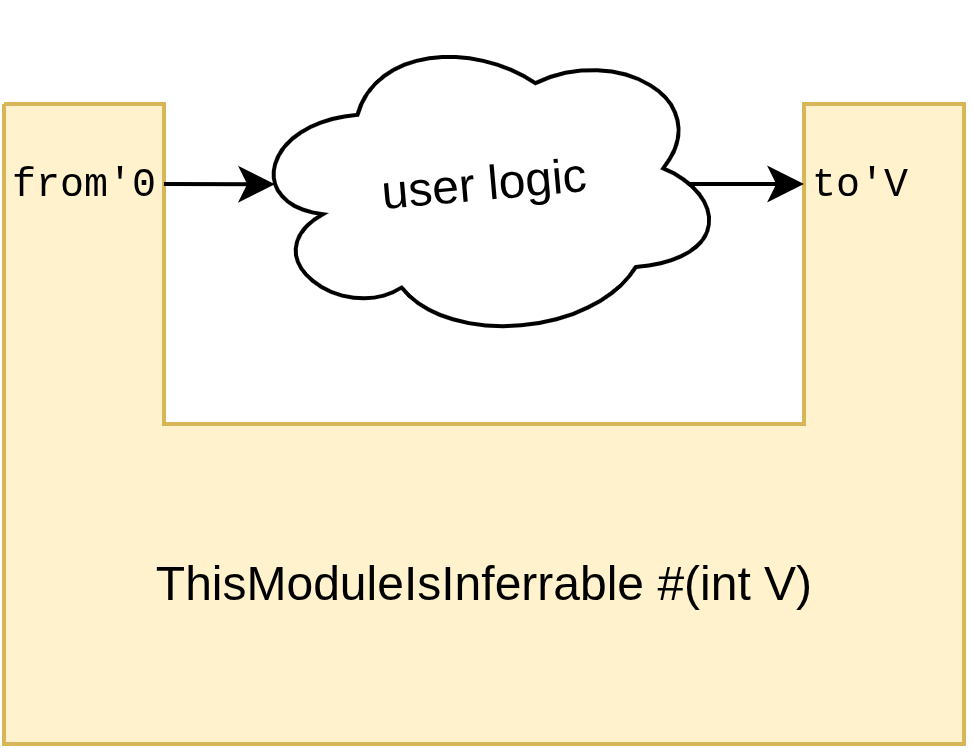
When some cloud of user logic is attached between the output from and input to, that has some number of pipeline stages. Let's say the user logic has 5 pipeline stages, then any value of V < 5 would cause a Net Positive Latency Cycle Error. Since there is only one place that can infer V, it will in fact be inferred to V=5. However, in the case there are multiple places in the module where the parameter can be inferred. In that case, perhaps a value higher than 5 might be chosen, if another constraint requires it.
Tip: Specify All Port Latencies for latency-sensitive modules.
For latency-sensitive modules, it is best to attach explicit latencies to all their ports, and to try to make these latencies as simple as possible. Any pair of ports between which the latency isn't known to be a constant from the annotations (such as '3 -> '7), or is inferrable (-V -> 3) 2, will be seen as a Poison edge.
which will not affect other inference attempts, since the assumption is that V will be inferred such as not to affect the surrounding pipeline.
For non-latency-sensitive modules usually don't need to have their port latencies specified explicitly, since they likely will be instantiated early, in which case exact latencies are known.
Tip: Be agressive in splitting latency-sensitive modules into separate domains Domain
Really, making latency sensitive modules is just an exercise in avoiding any and all Poison Edges. By splitting unrelated interfaces of the module into separate domains, no poison edges can be formed across the domain boundary. For an example of this, see FIFO.
Domains
Latency Domains are a way of splitting up temporally unrelated wires. Take for instance the FIFO:
module FIFO #(T, int DEPTH, int MAY_PUSH_LATENCY) {
domain push_dom
output bool may_push'-MAY_PUSH_LATENCY
action push'0 : T push_data'0
domain pop_dom
output bool may_pop'0
action pop'0 : -> T pop_data'1
domain reset
action rst
}
Similar to Clocks, the domain statement applies to all ports that are declared lexically after it. In the FIFO example, may_push, push, and push_data belong to domain push_dom, and may_pop, pop, and pop_data belong to pop_dom. The reset signal also goes into its own domain.
The push and push_data wires are clearly temporally linked. A high push signal is associated with a push_data value in that clock cycle and only that clock cycle. Indeed, a similar relationship exists between pop and pop_data, only in this case, the pop signal is associated with a pop_data value exactly one cycle later. Even may_push and push are closely linked, since a high value for may_push indicates that MAY_PUSH_LATENCY cycles later, push is allowed to go high. (In the case of FIFO, a may_push actually tells us that the FIFO has at least MAY_PUSH_LATENCY elements worth of space left).
Clearly, within the scope of "pushing" there are cycle-wise relationships, and within the scope of "popping" there are relationships, but there is no such direct cycle-to-cycle correspondence across these two scopes.
With domains, we make the lack of dependencies between the interfaces clear.
The benefits
If we were to keep all the wires in the same domain, we could run into Net Positive Latency Cycle Errors, or accidentally instantiate a large number of unneeded pipeline stages as the compiler unneccesarily compensates for the difference between two interfaces that should be unrelated.
Warning
It is easy to create invalid modules by being too liberal with declaring domains. For instance below:
module DisconnectDomains {
domain a_dom
input bool x'0
domain b_dom
output bool y'4 = x
}
With this module, it effectively instantiates 4 latency registers internally, but by adding the separate domains we've effectively severed any relationship of the ports to the outside world.
As a rule of thumb, you should only split up domains so far that the wires within a domain are fully self-sufficient for their own backpressure.
Resolving Latency Counting Errors
When working with the Latency Counting system, errors may crop up that may at first seem rather cryptic. Usually they stem from Latency Counting's rather stringent Solution Uniqueness requirement, and are therefore fairly trivial to resolve. Still, this article covers what causes each Latency Counting Error and provides strategies to resolve it.
Net Positive Latency Cycle
This is perhaps the most straight-forward of them all. You've created a loop in the pipeline, which makes it impossible to assign absolute latencies to your wires without violating the latency requirement of one of your submodules, or ignoring one of your reg requirements.
Example 1
module Accumulator {
state float cur_total
action accumulate : float value -> float total {
// Latency of +11
total = cur_total
cur_total = fp32_add(cur_total, value)
}
action rst {
cur_total = 0.0
}
}
In this example, we wish to accumulate floating point values as they come in, but we forgot to account for the 11 cycles of latency fp32_add takes. The compiler rightfully complains that there isn't enough time to compute the sum before it is required for the next addition.
Resolution 1: Use a better primitive
If it is available we can use a more appropriate primitive fp32_acc which does support single-cycle accumulation.
module Accumulator {
fp32_acc accumulator
action accumulate : float value -> float total {
// Latency of +11
total = accumulator.acc(value)
}
action rst {
accumulator.rst()
}
}
Resolution 2: Slow down the input stream
If our platform doesn't support fp32_acc, or our operation is so complicated that it cannot be reduced to a single clock cycle without degrading our clock frequency, we must find some other alternative.
If it turns out that this part of the computation isn't critical for the speed of our design, we can consider by lowering the "Initiation Interval" using SlowState, SlowPipelineBegin or SlowPipelineEnd.
module Accumulator {
SlowState#(T: type float, RESET_TO: 0.0) cur_total
trigger may_accumulate
action accumulate : float value -> float total {
float next_sum = fp32_add(cur_total.old, value) // Takes 11 cycles
cur_total.update(next_sum)
total = next_sum
}
when cur_total.may_update {
may_accumulate()
}
action rst {
cur_total.rst()
}
}
Resolution 3: Multiplex multiple parallel executions
Perhaps we don't just want to accumulate one stream of values, but we actually want to accumulate many different streams of values. We can multiplex these different streams together, using only a single instance of the feedback loop. With this, the iteration time of a single stream is not improved, but we're still using all the throughput this pipeline can provide.
module Accumulator {
// Choose 16 because it's a nice power of 2 above the 11 cycles of fp_add latency
gen int NUM_PARALLEL_ACCUMULATORS = 16
RAM#(T: type float, DEPTH: NUM_PARALLEL_ACCUMULATORS) cur_totals
trigger may_accumulate
action accumulate : float value, int#(FROM: 0, TO: NUM_PARALLEL_ACCUMULATORS) stream_id -> float total {
float cur_total = cur_totals.read(stream_id)
float next_sum = fp32_add(cur_total, value) // Takes 11 cycles
cur_totals.write(stream_id, next_sum)
total = next_sum
}
action rst {
cur_total.rst()
}
}
With this approach, we must make sure that the input does not touch the same stream_id twice within 13 cycles. (2 extra for the RAM).
For more other problems like iterative algoritms, you may be interested in ParallelWhile instead.
Example 2
module SetReset {
input bool set_true
input bool set_false
output state bool x = false
when !x & set_true {
reg x = true // <<<=== Incorrectly added `reg` here.
}
when x & set_false {
x = false
}
}
In this example, there is a subtle dependency between reading x in the condition, and setting x to true with a delay of 1 register. This dependency creates a net positive latency cycle of +1.
Resolution
In this case, of course we should remove the register, since a state variable already comes with a register. This example was meant to illustrate the subtle dependencies that can arise from the conditions on our when blocks.
Conflicting Specified Latencies
Quite similar to the Net Positive Latency Cycle, but in this case the difference in the Absolute Latencies you have explicitly assigned to two wires is smaller than the minimum latency the path between them actually takes.
Example
module ConflictingLatencies {
input bool i'0
output bool o'1 // <<<=== Conflicting Latency is reported here
reg bool t = i
reg o = t
}
In the above example, we've added two latency registers, but our explicit annotations setting i to absolute latency 0 and o to 1 conflicts with this.
Resolution
In this case the fix is rather easy, either reduce the amount of latency within the module, or adjust (or even remove) the absolute latency annotations.
Not Strongly Connected Ports
The first step in Latency Counting is always to figure out the absolute latencies of the ports. SUS' Latency Counting does this by performing graph traversals from every port, and finding the minimum distance the other ports that are connected to it. If there's no path between two ports, then the Latency Counting system cannot assign them a relative latency.
Example 1
module UnconnectedPort {
input bool i
output bool a
output bool b // <<<=== Not connected to i
reg a = i
b = true
}
Resolution
If we want to maintain a conceptual link between b and a values, despite in this case b being effectively constant, we should use explicit absolute latencies to pin them together:
module UnconnectedPort {
input bool i
output bool a'0
output bool b'0
reg a = i
b = true
}
However, if b is conceptually not directly linked to any one specific a value, instead you should consider putting b into a separate domain from a and i. By using separate domains for them, we make it clear on the interface that they are independent.
module UnconnectedPort {
domain a_dom
input bool i
output bool a
domain b_dom
output bool b
reg a = i
b = true
}
Example 2
module OnlyOutputs {
output state int minute
output state int hour
initial minute = 0
initial hour = 0
when minute == 59 {
hour = hour + 1 mod 24
}
minute = minute + 1 mod 60
}
In this example, there is logic connecting the hour and minute ports, but the compiler still complains. That is because there's no shared input port to measure the distances of hour and minute off of. In theory the compiler would be allowed to place these ports at an arbitrary offset from one another, and insert however many registers it wants.
Resolution
As with the previous example, the solution is to explicitly assign absolute latency values to minute and hour:
module OnlyOutputs {
output state int minute'0
output state int hour'0
initial minute = 0
initial hour = 0
when minute == 59 {
hour = hour + 1 mod 24
}
minute = minute + 1 mod 60
}
In this case, you might naturally say "Well clearly they should be at the same absolute latency", but in the general case it may not be unique. Extending the cases where Latency Counting can automatically make reasonable choices for such latencies is subject to ongoing research.
No Unique Port Latencies
This error comes back to the uniqueness issue. While the compiler could assign a set of absolute latencies to the ports, it notices that it is not the only possibility. That is because it cannot make the distances between all ports minimal at the same time.
Example
module ConfusingPorts {
input bool a
input bool b
output bool x
output bool y // <<<=== The error is reported on one of the ports
reg bool a_d = a
bool t = a_d + b
reg reg reg bool a_dd = a
reg bool t_d = t
x = t_d + a_dd
y = t
}
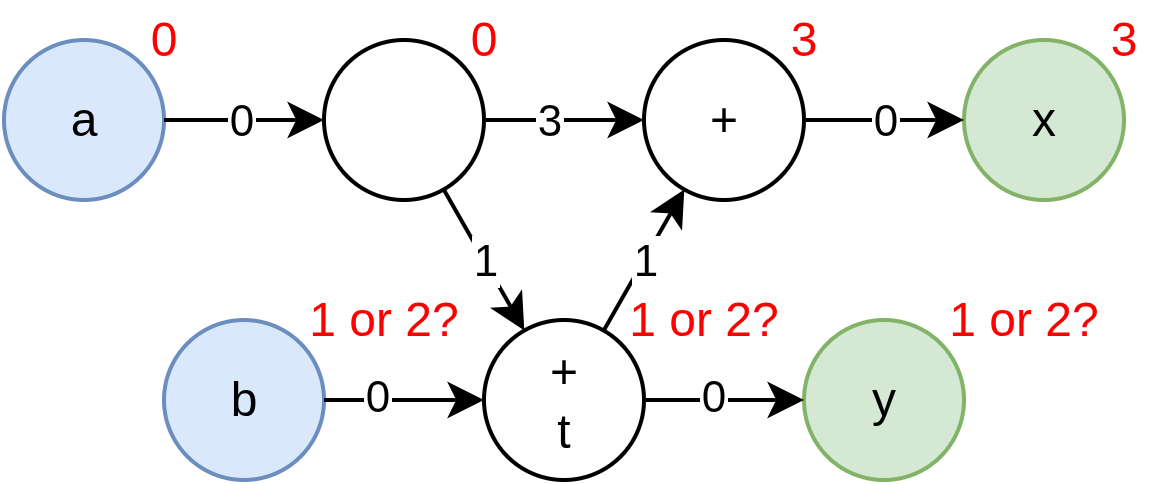
Have a look at the example above. Let's say an arbitrary absolute latency starting point of a'0 is chosen, then because the distance from it to x and y must be minimized, hence forcing x'3 and y'1. Counting back from x then would require b'2, but counting back from y would require b'1. If instead we chose to start at b'0, we would get a similar set of conflicts, requiring a'-2 from x'1, and a'-1 from y'0.
We cannot make a unique assignment of the absolute latencies for the ports, so we must request input from the programmer.
Resolution
Note that removing any of the ports resolves the issue. Removing b results in a'0, x'3, y'1, removing y gives a'0, x'3, b'2, etc.
Since straight-up removing ports is likely not an option for you, instead you can resolve the conflict by manually marking some ports with absolute latencies, such as a'0, b'1 resolves the conflict.
Luckily, undecidable structures such as we encountered here are rare in real designs.
Splits
Sometimes you're building more complicated hardware structures, and you find yourself in a situation where you've got a repetitive structure that you'd really really want to express as for loops over a series of intermediary arrays. Only, some constraint is holding you back. Perhaps you're implementing some type of cascading structure where Latency Counting inadvertently ties your array elements together causing Net Positive Latency Cycles.
An array declared as a split lets you get around this limitation. Each index in the outermost array becomes a separate wire, and any parameter of these wires not explicitly specified in the declaration can vary freely. Examples of parameters you can vary are:
- Absolute Latency (for
splitwires at multiple points in a pipeline) - Array sizes
- Integer bounds
Example
module AddFloats {
input float[16] floats
output float sum
split float[][5] float_reduction
// Results in:
// float[1] float_reduction_split_0'44
// float[2] float_reduction_split_1'33
// float[4] float_reduction_split_2'22
// float[8] float_reduction_split_3'11
// float[16] float_reduction_split_4'0
float_reduction[4] = input_floats
sum = float_reduction[0]
for int I in 0..4 {
gen int SIZE = pow2#(E: I)
float[SIZE] lefts = float_reduction[I+1][SIZE:]
float[SIZE] rights = float_reduction[I+1][:SIZE]
// We do have to declare sums as a temporary array here to help type inference
// May fix in future https://github.com/pc2/sus-compiler/issues/160
float[SIZE] sums
for int J in 0..SIZE {
sums[J] = fp32_add(lefts, rights)
}
float_reduction[I] = sums
}
}
In the above example, we've implemented a basic floating point TreeAdd. 16 floats are accepted, and a tree of 15 floating point adders from sus-float reduces this down to 1 float. We need split here because:
- We wish to halve the number of floats in each step. We couldn't declare this as a normal 2D array, because it would need to be a staggered array, which non-split wires don't support.
fp32_addhas a latency of 11 cycles on U280 FPGAs. Since we use the same variable for each pair of sequential layers, this would create a net-positive latency cycle fromfloat_reductionto itself. With the split,float_reduction[0]is a distinct wire fromfloat_reduction[1], which is distinct fromfloat_reduction[2], etc. Hence, allowing them to be at different absolute latencies.
Drawbacks of split
- You cannot use a runtime index into the "split" array dimension.
- The parameters of each wire in the split must be Inferred. This may lead to funky constructs.
- Ports cannot be declared
split(Yet... https://github.com/pc2/sus-compiler/issues/196) splitgenerates individual wires. This means in the waveform viewer it's slightly harder to discern.
Latency Counting Algorithm
Background: Bellman-Ford
Incorporate the Specified Latencies into the Latency Counting Graph
Check for Net-Positive Latency Cycles
Figure out Port Latencies
Fill in internal Latencies
Latency Inference
Poisoning
fp32_mul below is of unknown latency, and thus the edges between a -> result and b -> result are "Poison" edges.
Poison Edges are called as such because any Latency Inference probes that pass through them will become "poisoned", preventing inference if the target node of the Latency Inference probe lies in the poison edge's fanout. This is done because at the time of inference, the poison edge might hide an arbitrarily large latency, that could overpower any maximum latency assumed of it.
Usually, Poison edges just prevent premature inference, and are thus not a huge problem. Whatever modules poisoned the previous latency inference attempt likely get resolved in the next round of concrete typechecking, after which their exactly known latencies can be used to do the inference properly.
SUS Language Syntax
TODO
Operators
All operators SUS supports are shown in the below table. Higher rows have higher precedence, with array indexing ([]), function calls (()) and field access . having the highest precedence (binding the strongest), and the boolean binary operator | having the lowest precedence.
| Kind | Operator |
|---|---|
| postscript_op | [], (), . |
| unary | +, -, *, &, \|, ^, ! |
| multiplicative | *, /, % |
| additive | +, - |
| shift | <<, >> |
| modulo | mod |
| compare | ==, !=, <, <=, >, >= |
| and | & |
| xor | ^ |
| or | \| |
Tensors
TODO
Tensor Reductions
TODO
may_x then x() idiom
Many actions have a certain backpressure associated with them. A FIFO may not have space to push() into or a SlowState may not have stabilized yet. To indicate if a submodule is "ready" to take an action, we use a may_* output. If may_do_thing is low, then the parent module is not permitted to execute the corresponding do_thing() action. Now, this is just a convention, it is not enforced by the compiler.
may_x and x() can be offset from each other by an arbitrary latency (of course, with may_x still preceding x). For instance, FIFO's may_push signal is MAY_PUSH_LATENCY cycles ahead of the corresponding push signal, allowing the user to insert pipeline stages between them.
when input_fifo.may_pop & output_fifo.may_push {
int data = input_fifo.pop()
reg int data_twice = data + data
output_fifo.push(data_twice)
}
It may seem similar to your typical ready/valid handshake protocol (like AXIS), as ready is provided by the target module, and the source module asserts valid to indicate that its data is valid. The stark difference is that in AXI, a "transfer" only happens when both ready and valid are high, whereas do_thing() may not be high if may_do_thing is low. This is the difference that prevents free flowing pipelines in a protocol like AXI (due to the 0-cycle response time required when ready goes low), whereas the may_x/x() protocol permits it.
Debugging the SUS compiler
The SUS compiler has various ways to aid in debugging. These are listed below. All debugging code is found in src/debug.rs.
Debug Whitelist
Usually we only want to debug a specific module in which we can see that something is going wrong, but sadly, any breakpoint we place will be triggered by many other modules, and also standard library modules. By passing a debug whitelist we can restrict breakpoints and other debugging features to only occur while processing the module in question.
Pass sus_compiler --debug-whitelist module_name for flattening and all instantiations of the module_name, or sus_compiler --debug-whitelist "module_name #(PARAM_A: ..., PARAM_B: type ...)" for a specific instantiation. (BEWARE: The parameter list must be complete and in the same order of the template args as it is printed in the SUS log. The is_enabled circuitry just does substring matching)
If no whitelist is provided then debugging is enabled globally. Outside debug_context() debugging is also enabled globally.
Debug Optional Paths
These are optional paths that can be enabled at commandline. They allow for a more detailed look into the inner workings of the compiler. In the code they are marked by crate::debug::is_enabled("print-abstract").
| Flag | Effect |
|---|---|
--debug print-abstract | Prints the instructions+spans and their types after flattening and typechecking |
--debug print-abstract-pre-typecheck | Prints the instructions+spans after flattening but before typechecking |
--debug print-unused-vars-map | Used for debugging the "unused variable" warning. Prints the dependency graph of all instructions |
--debug print-execution-state | After each instruction is executed, prints the whole execution state |
--debug print-concrete | Prints the generated wires and their types for a given module instance after execution and concrete typechecking |
--debug print-concrete-pre-typecheck | Prints the generated wires for a given module instance before concrete typechecking |
--debug print-solve_latencies-test-case | Prints a #[test] case representation of the Latency Counting problem of a given module for use in src/latency/latency_algorithm.rs |
--debug print-infer_unknown_latency_edges-test-case | Prints a #[test] case representation of the Latency Inference Counting problem of a given module for use in src/latency/latency_algorithm.rs |
--debug dot-dependency-graph | Creates a {module_name}.dot file with a graph representation of the generated circuit |
--debug dot-latency-problem | Dot debug the problem graph for latency counting in solve_latencies_problem.dot |
--debug dot-latency-solution | Dot debug the solution graph for latency counting in solve_latencies_solution.dot |
--debug dot-latency-infer | Dot debug the problem graph for latency inference in latency_inference_problem.dot |
--debug dot-png | Use dot -Tpng to create a png file from generated dot files (Can be surprisingly slow, prefer svg) |
--debug dot-svg | Use dot -Tsvg to create a svg file from generated dot files |
--debug lsp-debug | Instead of regular LSP hover info, provide raw debug info |
--debug TEST | Temporary marker for debugging |
Crash Dumps
When the compiler panics, it dumps the contents of the user-specified files in $SUS_HOME/{version}/crash_dumps. Standard library files are not stored. Each crash is stored in a folder, named after the compiler stage, the module in which the crash took place, as well as a timestamp. Crashes can be reproduced by running sus_compiler --no-redump in the directory of the crash dump, as it will automatically include all .sus files in the directory. --no-redump should be used such that no duplicate dumps are created when reproducing the crash.
On some systems (notably our cluster), the SUS_HOME directory isn't writable. When a crash occurs, we'll try to write it to SUS_HOME/crash_dumps/<dump_name>, and if that fails we write to ./sus_crash_dumps/<dump_name>.
Crashes can also be debugged on master with the "Debug Crash Dump" .vscode/launch.json configuration.
Timeout crash
sus_compiler --kill-timeout 2.0 will enable a timeout killer that kills the compiler if any debug_context()-ed context takes longer than 2s to complete. Useful to prevent runaway LSPs. Disabled by default.
Breakpoints, debug prints, spans
All debug features abide by --debug-whitelist
| Name | Use |
| --- | --- |
| crate::debug::debug_context("typechecking", "module_name", \|\| {...}) | Everything inside the lambda runs within a debug context, enabling debugging if any item in --debug-whitelist is a substring of module_name. Can be nested. |
| if crate::debug::is_enabled("name") {...} | Check if --debug name is used |
| __debug_breakpoint!() | breakpoint |
| __debug_breakpoint_if!(x == 5) | conditional breakpoint |
| __debug_span!(span, "This here") | Show a span visually |
| __debug_dbg!(obj_a, obj_b, ...) | Equivalent to Rust's dbg!(obj_a, obj_b, ...) |
How SUS code is compiled
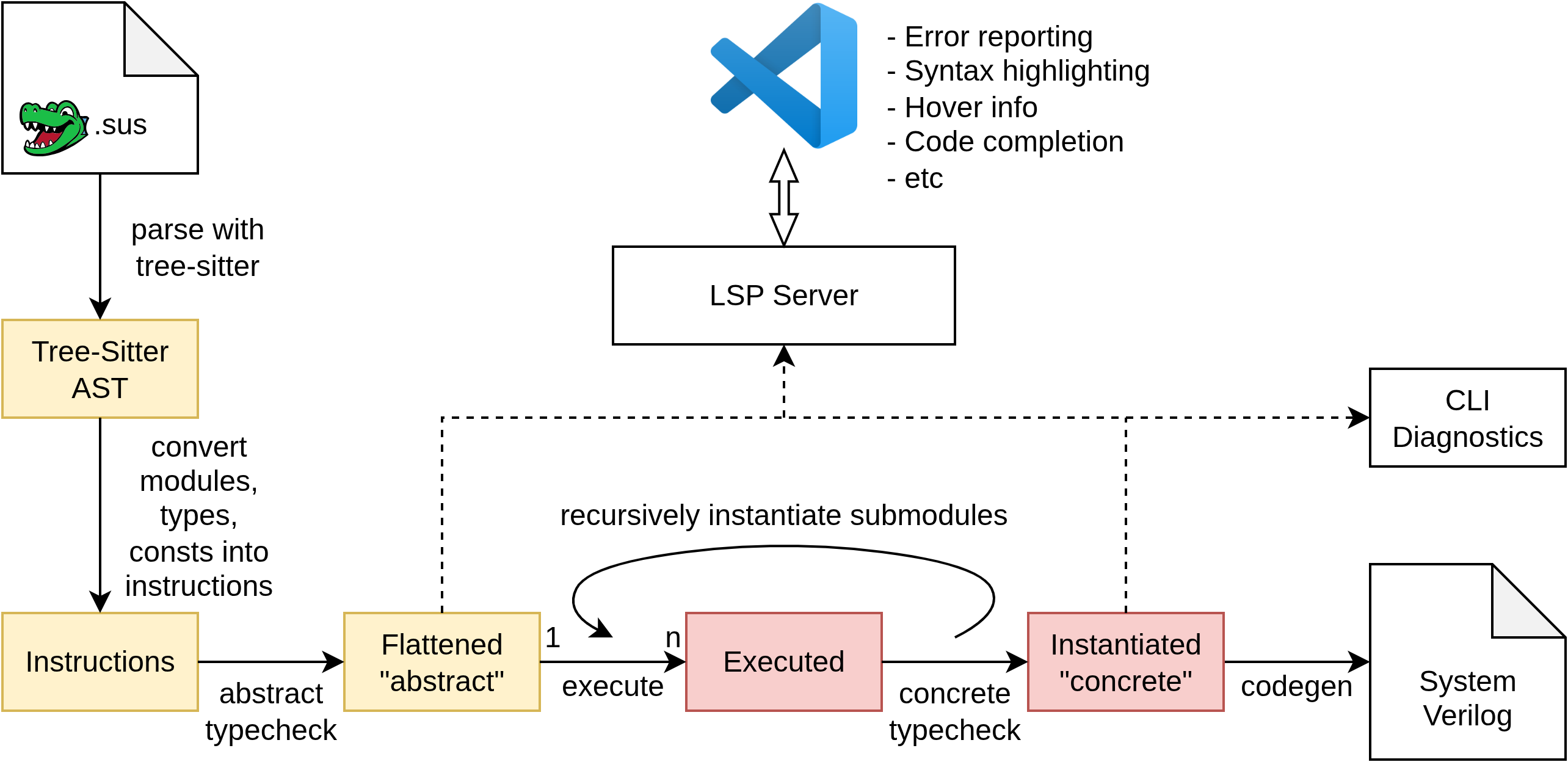
There are five major "stages" in the SUS compiler:
Parsing
Parsing is done using tree-sitter. Tree-Sitter was chosen due to its fast parse times and error tolerance. It generates an untyped syntax tree, with ERROR nodes representing invalid syntax. These error nodes are converted to diagnostics to let the programmer know what's up.
Flattening
The untyped syntax tree is then converted to a "flattened" variant. This is basically a sequence of instructions for compile-time execution. This list of instructions is still untuy
In this example, we'll look at a ToOneHot module, shown below.
module ToOneHot#(int SIZE) {
input int#(FROM: 0, TO: SIZE) idx
output bool[SIZE] bits
for int i in 0..5 {
bits[i] = idx == i
}
}
During parsing and flattening, the above module is turned into a sequence of instructions. Something roughly like:
$0: Declaration("SIZE", GenerativeParameter, "int", ...)
$2: Expression(IntConstant(0, ...))
$1: Expression(VarRead("SIZE", ...))
$3: Declaration("idx", Wire, "int#(FROM: $1, TO: $2)", ...)
$4: Expression(VarRead("SIZE", ...))
$5: Expression(IntConstant(0, ...))
$6: Expression(IntConstant(5, ...))
$7: Declaration("i", Generative, "int", ...)
$8: ForLoop(in: $7, from: $7, to: $8, body: $9-$13)
$9: Expression(VarRead("i", ...))
$10: Expression(VarRead("idx", ...))
$11: Expression(VarRead("i", ...))
$12: Expression(Operator($10, "==", $11, ...))
$13: Assign("bits[$9]", $12, ...)
Abstract Typechecking
All declared modules, structs, consts go through the abstract typing stage exactly once. During abstract typechecking stage, global names are resolved, module ports and struct fields are resolved, it is checked that rumtime values aren't passed to compiletime contexts, clock domains are assigned and checked for conflicts, and light typechecking (ensures int is not passed to a function requiring a bool for instance, but bounds aren't checked yet). Its main task is to catch all errors that can be caught, before concrete values are known for the object's Parameters.
In the ToOneHot module, the compiler finds no abstract typing errors, so we it is now ready for execution.
Execution
After the ToOneHot has been abstract-typechecked, it may be instantiated with some concrete arguments. In this case we chose ToOneHot#(SIZE: 5). The SUS compiler acts much like a simple imperative interpreter. Using loops and if statements as control flow, altering compile-time variables as written. When when statements, or other runtime statements like assigns and submodule instantiations are encountered, they are converted to wires/submodules to be included in the final design. Importantly, the types of these wires & submodules does not have to be fully known at execution time. Full resolution of these types and the instantiation of submodules only happens during Concrete Typechecking.
After executing all the compile-time code, we are left with a module that effectively looks like:
module ToOneHot_SIZE_5 {
input int#(FROM: 0, TO: 5) idx
output bool[5] bits
bits[0] = idx == 0
bits[1] = idx == 1
bits[2] = idx == 2
bits[3] = idx == 3
bits[4] = idx == 4
}

During execution, errors may crop up, such as array index out of bounds errors, divide by zero, etc. These immediately halt execution.
Note: Since you can execute arbitrary code at compiletime, compilation may take arbitrarily long or even hang forever if an infinite loop is created.
Concrete Typechecking
If after execution no errors came up, the instantiated module proceeds to the final stage. Here, any concrete values that cannot be generically checked from the abstract representation are checked or inferred. The bounds of integers, array sizes, and parameters of submodules are checked or inferred. When all of a submodule's parameters become known, it is instantiated recursively.
Let's say we've got another module:
module OneHotPlusOne {
input int#(FROM: 0, TO: 4) idx
output bool[] bits
int idx_plus_one = idx + 1
ToOneHot toh
toh.idx = idx_plus_one
bits = toh.bits
}
The bounds of idx_plus_one are inferred:
module OneHotPlusOne {
input int#(FROM: 0, TO: 4) idx
output bool[] bits
int#(FROM: 1, TO: 5) idx_plus_one = idx + 1
ToOneHot toh
toh.idx = idx_plus_one
bits = toh.bits
}
From this, the SIZE parameter of toh is inferred:
module OneHotPlusOne {
input int#(FROM: 0, TO: 4) idx
output bool[] bits
int#(FROM: 1, TO: 5) idx_plus_one = idx + 1 // *
ToOneHot#(SIZE: 5) toh
toh.idx = idx_plus_one
bits = toh.bits
}
ToOneHot#(SIZE: 5) is instantiated as ToOneHot_SIZE_5, and since its output port output bool[5] bits has a known size, we infer that our bits output should also have size 5:
module OneHotPlusOne {
input int#(FROM: 0, TO: 4) idx
output bool[5] bits // *
int#(FROM: 1, TO: 5) idx_plus_one = idx + 1
ToOneHot_SIZE_5 toh // *
toh.idx = idx_plus_one
bits = toh.bits
}
Finally, although we didn't cover it in this section, Latency Counting occurs here too.
Using Xilinx' Integrated Logic Analyzer for SUS Designs
If your simulator has failed you, and you're pulling out your hair staring at a failing hardware implementation, your last resort is the Integrated Logic Analyzer. This is a small IP core that you instantiate into your design, which upon detecting a triggering signal, records all probe signals for 16384 cycles in its in-built BRAM. It only has inputs, and the IP core itself figures out how to connect itself to the JTag interface on the FPGA card. You need only instantiate it and wire it up to your signals.
The example in this tutorial is for using it within a SUS kernel in XRT on Noctua 2
Overview
Part 1: Synthesizing a design with an Integrated Logic Analyzer
- Wire up an "extern" ILA module, to all the signals you would like to view.
- Creating the
my_cool_ilaIP core inpack_kernel.tcl. - Synthesize your design. (Your kernel can be instantiated multiple times, Vivado automatically finds the ILA cores and connects them to it's debugging system)
Part 2: Running your design and viewing the recorded ILA data
- Open VNC on one of the FPGA nodes
- Load the Bitstream
- Open the vivado "Hardware Debugger"
- Set up your triggers
- Activate the ILA
- Execute your program
- Observe Waveforms
Part 1: Synthesizing
Wire up an "extern" ILA module, to all the signals you would like to view.
In my case, I wanted to debug the AXI4 interface to memory for the Bursting Memory Writer.
Start by creating an extern module for the ILA. In the next section we will instantiate the ILA IP core, but for now we'll declare it's interface, with all the probes we would want to view. They must be named probeN in ascending order.
(You can specify the widths of up to 1024 probes. By default they are 1-bit wide.)
extern module my_cool_ila{
domain clk
input bool probe0'0
input bool probe1'0
input bool probe2'0
input bool probe3'0
input bool probe4'0
input int#(FROM: 0, TO: 256) probe5'0
input bool probe6'0
input bool probe7'0
input bool probe8'0
input bool probe9'0
input bool probe10'0
input bool[2] probe11'0
input bool probe12'0
input bool probe13'0
input int#(FROM: 0, TO: 32) probe14'0
input bool probe15'0
input bool probe16'0
input bool probe17'0
input int#(FROM: 0, TO: pow2#(E: 32)) probe18'0
input int#(FROM: 0, TO: pow2#(E: 32)) probe19'0
}
I put every signal into its own domain, such that no pipelining registers would affect the view of the signals. Perhaps if you're debugging a pipeline, this may be desirable. Adjust to taste.
Important: Note that the ports that aren't bool correspond to the wider integers
Once you have the extern module my_cool_ila, instantiate it and wire it up:
module bench_burst_writer#(int AXI_WIDTH) {
// ...
my_cool_ila ila
ila.probe0 = aresetn
ila.probe1 = ila_start
ila.probe2 = ila_finish
ila.probe3 = m_axi_awvalid
ila.probe4 = m_axi_awready
ila.probe5 = m_axi_awlen
ila.probe6 = m_axi_wvalid
ila.probe7 = m_axi_wready
ila.probe8 = m_axi_wlast
ila.probe9 = m_axi_bvalid
ila.probe10 = m_axi_bready
ila.probe11 = m_axi_bresp
ila.probe12 = writer.may_write
ila.probe13 = writer.write
ila.probe14 = writer.element_count
ila.probe15 = writer.write_is_last
ila.probe16 = grab_new_transfer
ila.probe17 = num_left_to_transfer_valid
ila.probe18 = num_left_to_transfer
ila.probe19 = num_repeats_remaining_to_finish
}
Important considerations for wiring it up:
You'll want a signal you can trigger the ILA on, as it can only . In this case, I used the start wire the axi_ctrl_slave produces.
Note: There's no need to explicitly specify that a given signal is your trigger right now. The ILA has functionality to be dynamically reconfigured to trigger on a wide range of conditions
When choosing what signals to probe, consider carefully. Add any signal you believe might be useful in tracking down your issue, since a synthesis roundtrip can easily take 3 hours.
Adding the IP core to pack_kernel.tcl
Now that you have the as-of-yet undefined ILA wired up in your SUS design, you can expliticly create it in your pack_kernel.tcl:
# Existing pack_kernel.tcl code...
set KERNEL_NAME burst_writer${AXI_WIDTH}
create_project ${KERNEL_NAME} ./${KERNEL_NAME} -part $PART
add_files -norecurse \
{
../../sus_codegen.sv \
}
# Add these lines:
create_ip \
-name ila \
-vendor xilinx.com \
-library ip \
-version 6.2 \
-module_name my_cool_ila \
-dir ./ip_creation
set_property -dict [list \
CONFIG.C_MONITOR_TYPE {Native} \
CONFIG.C_NUM_OF_PROBES {20} \
CONFIG.C_PROBE5_WIDTH {8} \
CONFIG.C_PROBE11_WIDTH {2} \
CONFIG.C_PROBE14_WIDTH {5} \
CONFIG.C_PROBE18_WIDTH {32} \
CONFIG.C_PROBE19_WIDTH {32} \
CONFIG.C_DATA_DEPTH {16384} \
CONFIG.C_TRIGOUT_EN {false} \
CONFIG.C_TRIGIN_EN {false} \
CONFIG.C_INPUT_PIPE_STAGES {0} \
CONFIG.C_EN_STRG_QUAL {1} \
CONFIG.C_ADV_TRIGGER {true} \
CONFIG.ALL_PROBE_SAME_MU {true} \
] [get_ips my_cool_ila]
# the rest of pack_kernel.tcl ....
ipx::package_project -root_dir ./${KERNEL_NAME}_ip -vendor pc2 -library sus-designs -taxonomy /UserIP -import_files
You can configure CONFIG.C_DATA_DEPTH to a reasonable value for how much data you wish to collect in a single run. Note that this times the number of probe bits determines how much BRAM this ILA will synthesize.
You can specify up to 1024 probes. By default they are 1-bit wide.
For more configuration options, it is recommended to create the "ILA" IP core in Vivado, configure it in GUI, and copy over the generated TCL code from the TCL Console.
Note: ILAs consume BRAMs to store their samples. You must have enough free BRAM resources to store all samples. You may need to be conservative with the amount of cycles you record as you may quickly run out of BRAMs.
Note: ILAs cannot use URAMs
And synthesize!

This should be your normal way to build your bitstream. For this repository, that would be make U280/overlay_hw.xclbin
When your flow doesn't generate a .ltx file
The .ltx file contains information about your ILAs. Namely the names of the debug probes and their sizes. You need to load in this file to look at the waveforms.
You don't need to follow this step if you're using XRT.
Normally, when you write the bitstream, a .ltx file should be generated automatically. If it is not, you can open up your implemented Vivado project, and execute the following TCL command:
write_debug_probes /path/to/file.ltx
Part 2: Analyzing
Open VNC on one of the FPGA nodes
Use the VNC module on Noctua2:
[lennartv@n2fpga16 ~]$ ml tools/vnc/8.10
[lennartv@n2fpga16 ~]$ VNC.sh
This will print an SSH command, like the following:
#############
ssh -L 5901:/tmp/lennartv.runtimedir/vnc1 n2fpga16
Afterwards connect with your local VNC client to your local port 5901
#############
Use this ssh command to connect to the node.
Since you likely don't yet have the fpga or compute nodes in your .ssh/config, here's a snippet that should help you:
Host noctua2-jump
HostName fe.noctua2.pc2.uni-paderborn.de
User lennartv
RequestTTY force
IdentityFile ~/.ssh/id_ed25519
IdentitiesOnly yes
Host n2login1
HostName n2login1
User lennartv
ProxyJump noctua2-jump
Host n2cn* n2gpu* n2fpga*
HostName %h
ProxyJump n2login1
User lennartv
Load the Bitstream
You should be on a node with your FPGA. First and foremost, load your program once, such that the bitstream has been loaded onto the FPGA. If you're working with a system such as tapasco and you have a .bit bitstream file, you can also just flash the bitstream with tapasco-load-bitstream bitstream.bit.
Optional: Add a way to "pause" your host code after the bitstream loads (and before any kernel invocation you may want to inspect)
void debug_pause() {
std::cout << "Paused, press ENTER to continue..." << std::endl;
std::cin.ignore(std::numeric_limits<std::streamsize>::max(), '\n');
}
void main() {
xrt::device device = xrt::device("0000:a1:00.1");
xrt::xclbin xclbin = xrt::xclbin("overlay_hw.xclbin");
xrt::uuid xclbin_handle_ptr = xrt::uuid(device.load_xclbin(xclbin));
debug_pause();
// start running kernels
}
Run your host code until it hits the pause block
./main.x
Open the vivado "Hardware Debugger"
Create a new terminal and run debug_hw --vivado --ltx_file /path/to/file.ltx. This should open the hardware manager with your LTX file opened.
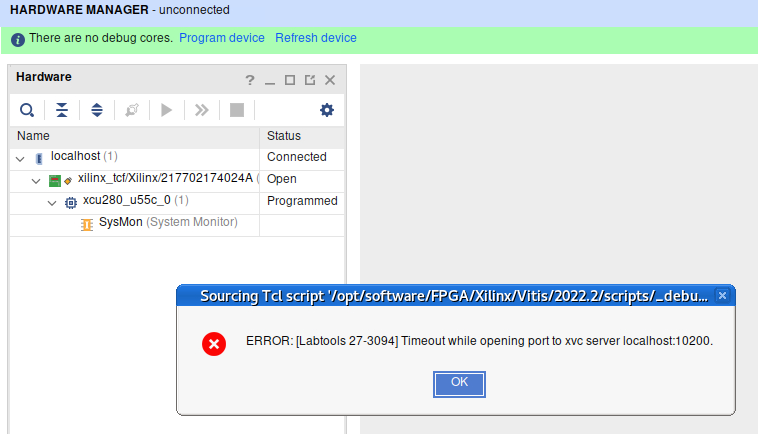
It may open in a broken state, and in this case, refresh the "localhost" debug server. Then, connect to your card with "Auto Connect".
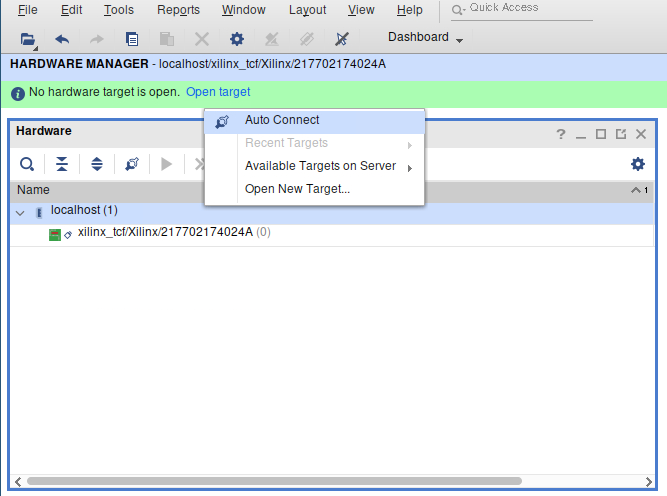
It should now show all your ILAs. Select one of your ILAs.
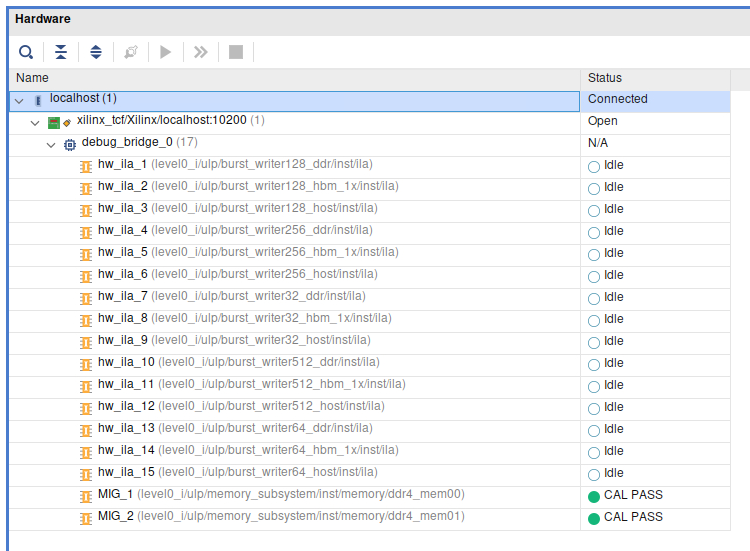
If it doesn't show your probes yet, load your .ltx file by clicking "Specify the probes file and refresh the device".
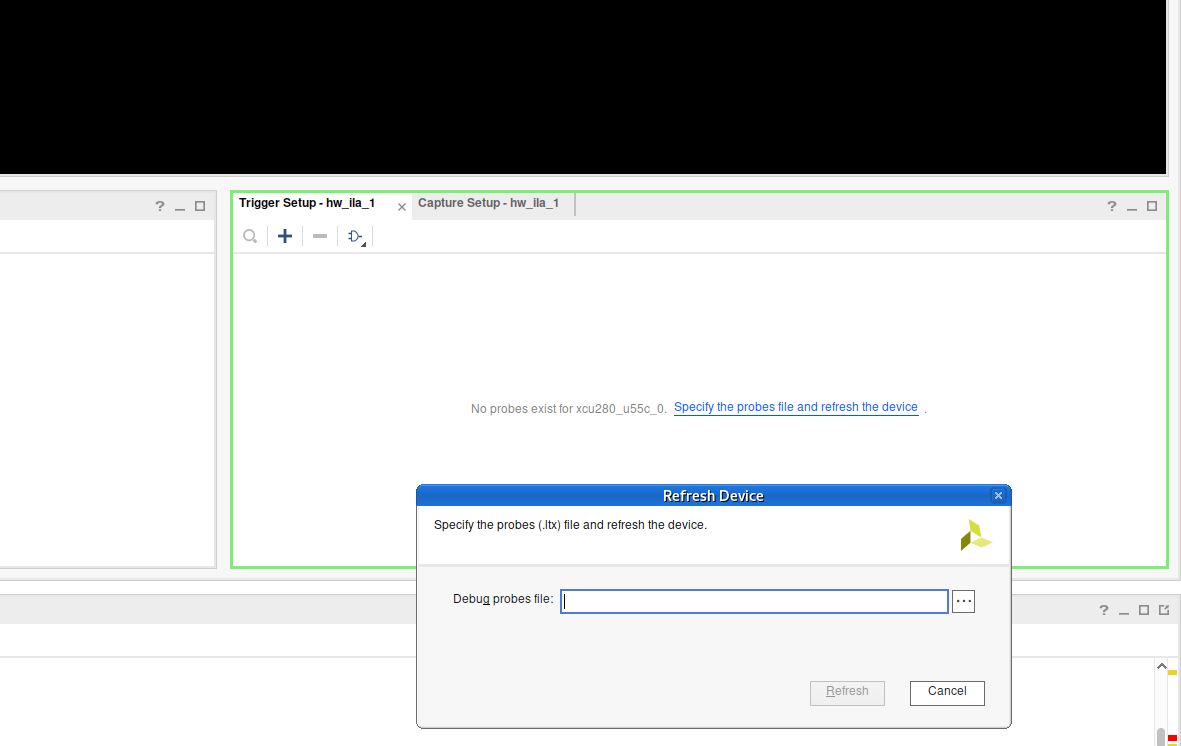
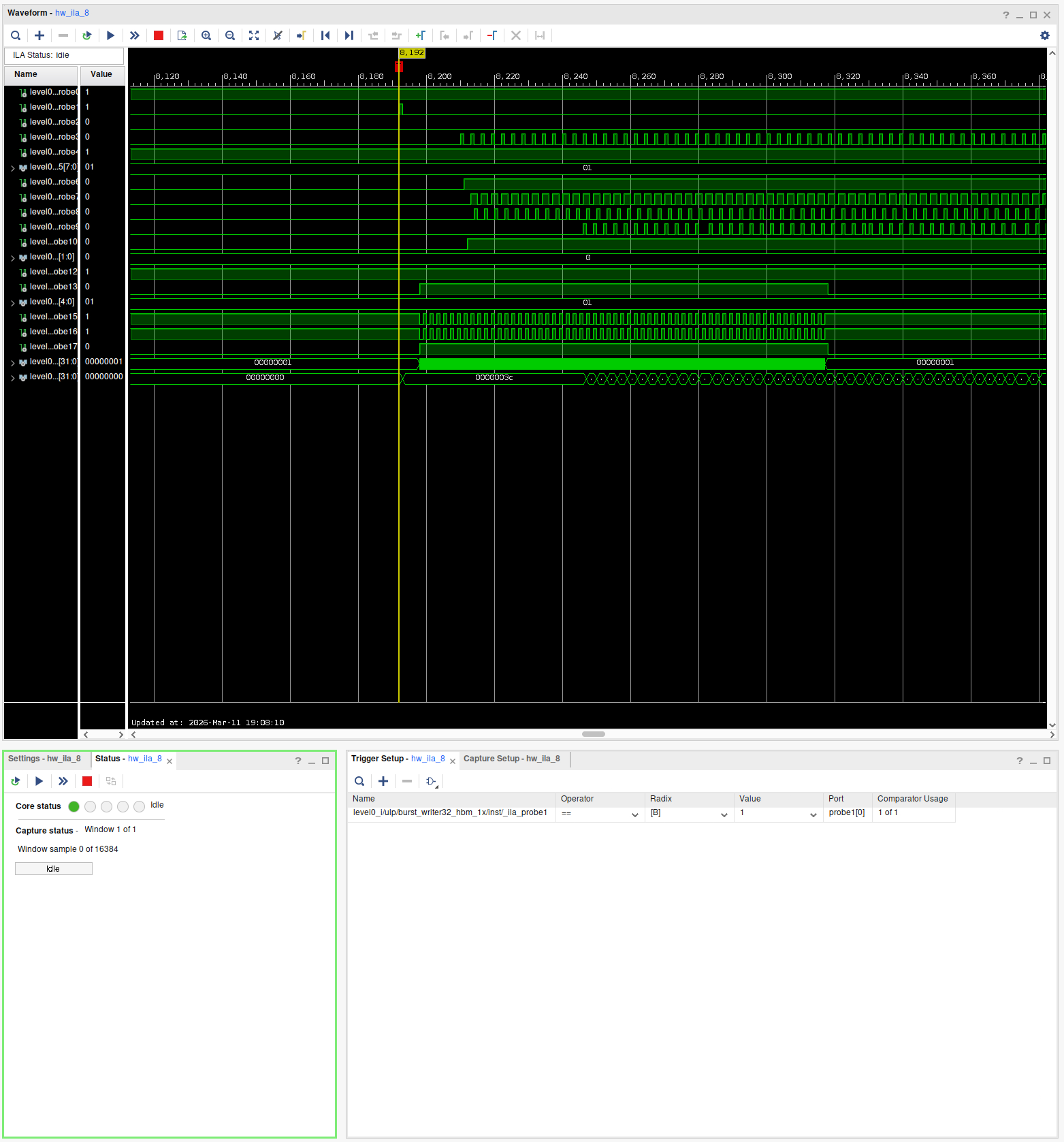
You can see the waveforms in the main panel, bottom left you see the current status of the selected ILA. Bottom right are the triggers.
Set up your triggers
On the bottom right, add a trigger. A trigger is a condition that the ILA looks for to start recording samples. This is because the memory to store samples is limited, and you only want to record the time span you're actually interested in.
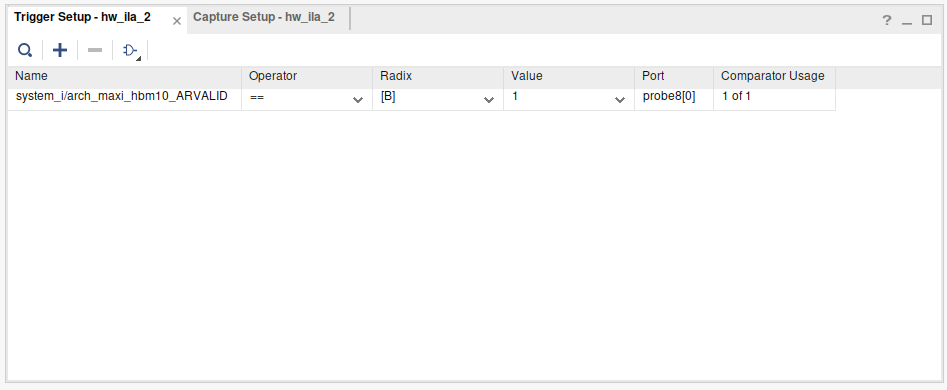
A detailed documentation on using the hardware manager and setting the triggers can be found here: https://docs.xilinx.com/r/en-US/ug908-vivado-programming-debugging/Connecting-to-the-Hardware-Target-and-Programming-the-Device?tocId=xP8mrtmlSr~QgWEr5ZpJWA
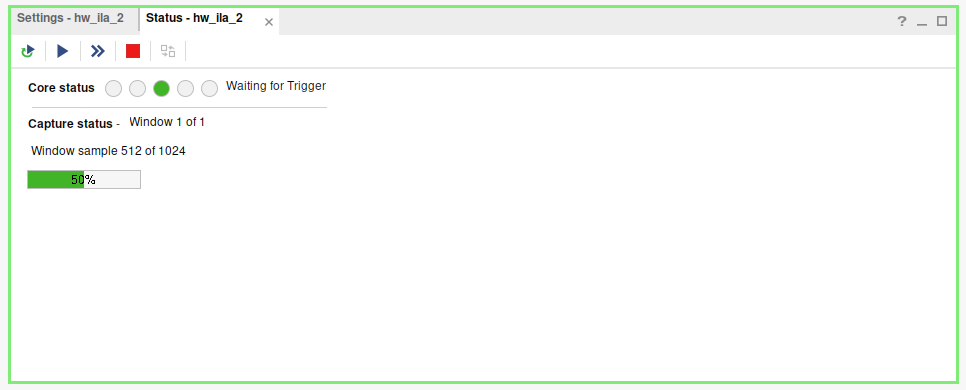
Activate the ILA.
"activate" the ILA on the bottom left. It will start collecting samples filling up half the buffer. Once the condition for your trigger is met, it will collect samples to fill the remainder of the buffer. You can configure where this midpoint is.
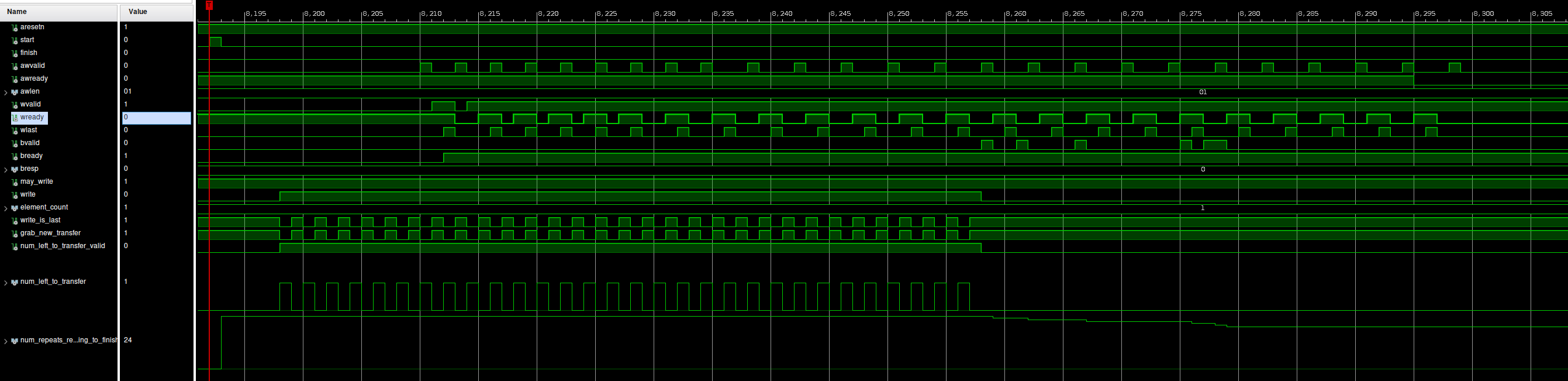
Continue execution of your executable.
Run your design. In doing this, your design should trigger the ILA you've activated. When you go back to the hardware manager, you should see some nice waveforms.
Bonus: Can you spot the AXI violation?
Separating Compiletime and Runtime
Requirements:
- Code that describes plain hardware should be minimal to write. One shouldn't have to 'break out' of the generative environment to write plain hardware code.
- It should be easy to write generative code mixed with plain hardware.
Differences
Compile Time
Arrays need not be bounded. Integers need not be bounded.
Runtime
Arrays that have dynamic indices must have a fixed size. Integers must be bounded.
Multiplexer inference
There is quite a significant difference between an array access with a constant, and one which should infer a multiplexer, but in both cases the syntax in other languages is exactly the same: my_arr[idx]
The constant index should infer to just a wire connection which costs nothing. In this case the different wires that are part of an array don't have any relation to each other in hardware. This allows us to bestow other properties as well. For example constant indices don't conflict with each other if they don't point to the same element. Runtime indices do. Array wires with constant indices don't enforce any latency requirements upon each other. 'dynamically sized' arrays can only be indexed with compile time indices. Etc.
With a runtime index (based on an integer wire in the design) should infer to a multiplexer. And then of course the array wires do have a relation.
An initial thought to distinguish the two was to just check for constant-ness of the array argument, which can be done at flattening time. But that wouldn't make the distinction clear enough.
Proposal: Require mux keyword for any runtime array index which should infer to a multiplexer.
Examples:
a[5] = 1constant index writea[mux b] = 1multiplexed writex = a[5]constant index readx = a[mux b]multiplexed index write
Control Flow
While hardware doesn't actually have control flow, it is often useful to have generative control flow for repeating hardware structures.
if
The humble if statement is the most basic form of control flow. It comes in two flavors: generation time, and runtime.
Generation time if
If its condition is met, then the code in its block is executed. It can optionally have an else block, which then also allows chaining else if statements.
Example
gen int a
gen bool b
if a == 5 {
// Do the first thing
} else if b {
// otherwise do something here
} else {
// etc
}
Runtime if
In practice, the biggest difference between these variants is that the code within both branches of the runtime if is executed regardless of the condition. Only assignments are performed conditionally. This means any assignments within the block will have a combinatorial dependency on the condition wire. To avoid confusion, it is not allowed to assign to generative variables within a runtime if.
Example
module m {
interface m : int a, bool b -> int c
if a == 5 {
c = 4
} else if b {
c = 2
} else {
c = 1
}
}
Conditional bindings
In hardware design, pretty much all data signals will be coupled with valid signals. Having dedicated syntactic sugar for this is thus valuable to lift some mental load for the hardware designer.
As an example, take the pop interface of a FIFO.
interface pop : bool do_pop -> bool pop_valid, T data
This is both an action (setting the do_pop signal), but also may fail (pop_valid). Both control signals can be hidden with this syntactic sugar. Furthermore, the output data of the FIFO is only available when the pop was successful. This adds nice implicit semantics that for example the formal verifier could then check.
FIFO myFifo
if myFifo.pop() : T data {
...
}
Which is equivalent to this:
FIFO myFifo
myFifo.do_pop = true
if myFifo.pop_valid {
T data = myFifo.data_out
...
}
This syntax can also be used to approximate imperative control flow. We would want something in hardware like the lambda functions in software, but what semantics should they have? As a first approximation, we can have the submodule 'trigger' some of our hardware using this validity logic. In this example we use a submodule that generates an index stream of valid matrix indices, and calls our code with that:
MatrixIterator mit
state bool start
initial start = true
if start {
mit.start(40, 40)
start = false
}
if mit.next() : int x, int y {
...
}
Finally, this might be a good syntax alternative for implementing Sum Types. Sum types map weirdly to hardware, as their mere existence may or may not introduce wire dependencies on the variants, depending on how the wires were reused. Instead, we could use these conditional bindings to make a bootleg match:
if my_instruction.is_jump() : int target_addr {
...
}
if my_instruction.is_add() : int reg_a, int reg_b, int reg_target {
...
}
for
The for statement only comes in its generative form. It's used to generate repetitive hardware.
Example
module add_stuff_to_indices {
interface add_stuff_to_indices : int[10] values -> int[10] added_values
int[5] arr
for int i in 0..10 {
int t = values[i]
added_values[i] = t + i
int tt = arr[i] + values[0]
}
}
while
Similar to the for loop. Also generation only. Not yet implemented.
chain and first
the chain construct is one of SUS' unique features. Not yet implemented.
Often it is needed to have some kind of priority encoding in hardware. It only fires the first time it is valid.
As a bit of syntactic sugar, the first statement uses a chain to check if it's the first time the condition was valid.
It comes in two variants: standalone first and if first.
Examples
module first_enabled_bit {
interface first_enabled_bit : bool[10] values -> bool[10] is_first_bit
chain bool found = false
for int i in 0..10 {
if values[i] {
first in found {
// First i for which values[i]==true
is_first_bit[i] = true
} else {
// values[i]==true but not the first
is_first_bit[i] = false
}
} else {
// values[i]!=true
is_first_bit[i] = false
}
}
}
With if first we can merge both else blocks.
module first_enabled_bit {
interface first_enabled_bit : bool[10] values -> bool[10] is_first_bit
chain bool found = false
for int i in 0..10 {
if first values[i] in found {
// First i for which values[i]==true
is_first_bit[i] = true
} else {
// values[i]!=true or not first values[i]==true
is_first_bit[i] = false
}
}
}
Often with uses of first one also wants to have a case where the condition never was valid.
module first_enabled_bit_index {
interface first_enabled_bit_index : bool[10] values -> int first_bit, bool all_zero
chain bool found = false
for int i in 0..10 {
if first values[i] in found {
first_bit = i
all_zero = false
}
}
if !found {
all_zero = true
}
}
Design Decisions
Why only allow reg on assignments, and not in the middle of expressions?
Because Hardware synthesis tools will report timing violations from register to register.
Because temporaries generate unreadable register names, having registers on temporaries would make for incomprehensible timing reports.
By forcing the programmer to only add registers (both state and reg) that are explicitly named, we ensure that timing reports will
always have proper names to point to.
Why C-style declarations instead of the more modern Rust/Scala-like type annotations?
In other words: Why int x = 5 instead of let x : int = 5?
There's two reasons for this:
- In hardware design, the types of wires should always be visible. Especially with SUS' "you-get-what-you-see" philosophy, the type of a variable tells you how many wires it is comprised of. This has real impacts on the considerations designers make when designing hardware.
- Hardware types tend to be simple, therefore small, and therefore it's not a huge cost to force the programmer to write them out, always.
Why bounded integers instead of bitvectors?
Why use tree-sitter as the compiler frontend?
In fact, several people within the tree-sitter ecosystem advise against using it as a parser frontend. The arguments given are that while tree-sitter has the fault tolerance one would desire for a compiler frontend, getting information on how to resolve these errors such as an expected token list is not yet implemented. Another argument given is that using TreeCursor is incredibly cumbersome.
I had originally written my own tokenizer, bracket matcher, and parser from scratch, and this got me through most of the major syntax I needed for a basic language. However, editing the language syntax became cumbersome, and bugs kept sneaking into the parsing phase. While this allowed me to be very informative in reporting the types of syntax error recovery I explicitly implemented, the slow development cycle, and my certain future inability to implement some of the more tricky parsing situations, such as templates, drove me to seek a prebuilt parsing library.
I tried the mainstream parsing libraries. nom, PEST and chumsky. These were often recommended to people seeking parser libraries for programming languages. But as I explored them, I ran into various issues. nom didn't support error recovery, PEST had weird issues in getting its grammar to accept whitespace, and chumsky's approach of encoding the whole grammar within the type system made for ridiculous compile times and impossible to debug typing errors.
A big thing all of these issues stem from is all of these libraries' insistence on a typed syntax tree. While this seems like a good idea, it makes it difficult to properly embed error nodes in the syntax tree. tree-sitter's barebones interface to its untyped syntax tree with error nodes is fine in this case, and it gives tree-sitter the benefit of much simplified memory allocation strategy.
Speaking of performance, tree-sitter's performance is absolutely unmatched. Especially because SUS intends to provide instantaneous feedback to the user, as they write their code, speed is essential. Tree-sitter's incremental updates feature is then icing on the cake.
Of course, dealing with tree-sitter's stateful TreeCursor object to traverse the syntax tree is difficult, especially in a language like Rust that doesn't like mutable objects. I was able to build a nice abstraction, called Cursor that abstracts away the mutable bookkeeping of TreeCursor, and presents a 'monad-like' interface for decending down syntax tree branches easily. It is defined in parser.rs.
How should 'function-like' modules be written?
So in software design, the idea of a function is straight-forward. It is a block of code, that receives some input, and then produces some output. The moment the function is called, it is brought into existence, does its task, and then once it completes it and returns the output, ceases to exist again.
In hardware however, modules are persistent. They are continuously receiving inputs, and continuously delivering outputs. Modules may even have multiple interfaces that are in operation simultaneously. This is why in many HDLs modules are instantiated, and then connected to the outside world by explicitly connecting wires to all their ports. Of course many modules people write will be quite 'function-like', and so we want to allow a shorthand notation for this. As an added bonus, 'function-like' modules may be able to be run in compile-time contexts.
Why co-develop Compiler and LSP in the same project?
A big factor in SUS' design is the incredibly tight design loop for the programmer. The LSP is an integral part of the experience SUS aims to deliver.
In fact, an important litmus test for new language features is how they affect the LSP for the compiler. For instance function/module overloading is a bad feature, because it reduces the LSPs ability to provide documentation on hover and completions in template contexts.
How to ensure good LSP suggestions, even in the context of templates?
How to allow optional ports on module, determined by compile-time parameters?
How should multi-clock designs be represented?
Multi-Dimensional array indexing does not use reference semantics.
Instantiation Modifiers
Because we have a broader vocabulary describing our modules, it becomes possible to modify instantiations of modules to add functionality.
- Continuous (default): The module behaves like a freestanding module, inputs and outputs are expected on each clock pulse
- Push: The module only advances when instructed by the parent module. This only affects
stateregisters. Latency is unaffected.
Additional modifiers
- Latency-free: All latency registers are removed
- Set latency: sets the latency between two connectors (ports, locals, fields etc), adding or removing latency registers as needed. Mustly used to override latency for tight feedback loops.
Structs and Modules and Constants
So structs, modules and constants all very much look alike in a certain sense. But modules must be distinct from structs and constants. Because Modules cannot be freely copied or moved around. But, one would want it possible to instantiate modules in arrays.
Templates
Template - Flow - Lifetime dichotomy
When instantiating
Interfaces
A module can have one or more interfaces, each of which consists of multiple input and output ports.
Interfaces form the only method by which one can cross latency and clock domains. Each interface has with it its associated hardware, that operates within the same clock and latency counting domain. Wires which belong to the same latency counting group should be placed in the same interface.
The code in one interface can read wires from other interfaces, provided the proper clock domain crossing method is used, in case of a clock domain crossing. Writes however, can naturally only be done by the interface that owns that wire.
To transfer data from one interface to another, use the cross keyword. To ensure that multiple wires stay in sync when needed, you can cross multiple wires together: cross wire_a, wire_b, wire_c. This ensures that any relative latencies are maintained in the target interface. Latencies are not kept in sync for wires in separate cross statements.
Examples
Example implementation of memory_block:
module memory_block<gen int DEPTH, T> {
interface write : T data, int addr, bool wr {
T[DEPTH] memory
if wr {
memory[addr] = data
}
}
interface read : int addr -> T data {
cross memory
data = memory[addr]
}
}
Actually, we can implement rebase_latency from latency.md.
Example implementation of rebase_latency:
// This module rebases the latency by an offset DELTA without adding registers.
module rebase_latency<gen int DELTA, T> : T data_in'0 -> T data_out'DELTA {
cross cross_o
data_out = cross_o
// Create an anonymous interface, such that we can break the latency dependency.
interface _ {
cross data_in
T cross_o = a
}
}
Latency Counting
For state see state
Combinatorial loops with latency are still combinatorial loops
This is in my opinion a big benefit to making the distinction. When inserting latency registers, we are saying in effect "If we could perform these computations instantaneously, we would", and thus, a loop containing latency registers would still be a combinatorial loop. Sadly, this does break down a little when explicitly building a pipelined loop. Also combinatorial dependencies could show up across interfaces as well. Perhaps we should rethink this feature.
Latency counting with state
Of course, state registers are also moved around by latency. This means that while it appears like (and we want the programmer's mental model to say that) two state registers get updated at the same time, they may actually be offset from one another in time.
However, state registers do not count towards the latency count. So specifying reg increases the latency count by 1, but specifying state does not. This makes sense, because state registers are meant to carry data across cycles, whereas latency registers are only meant for meeting timing closure, and don't allow sequential data packets to interact.
Maximum Latency Requirements
It's the intention of the language to hide fixed-size latency as much as possible, making it easy to create pipelined designs.
Often however, there are limits to how long latency is allowed to be. The most common case is a state to itself feedback loop. If a state register must be updated every cycle, and it depends on itself, the loopback computation path may not include any latency.
For example, a FIFO with an almost_full threshold of N, may have at most a ready_out -> valid_in latency of N.
For state to state paths, this could be relaxed in several ways:
- If it is proven the register won't be read for some cycles, then the latency can be hidden in these cycles. (Requires complex validity checking)
- Slow the rate of state updating to the maximum latency, possibly allow automatic C-Slowing.
Breaking out of latency counting
Feed-forward pipelines are an important and useful construct. But feed forward pipelines can't describe all hardware. We need to be able to break out of the latency counting system, and tell the latency counting system that there exists a latency differential between two nodes, without instantiating registers between them. In the case of making a dependent latency earlier than the source one, we call this edge a 'negative backedge'. This should be provided as a template module in the standard library:
module rebase_latency<T, gen int delta> : T i'0 -> T o'delta {/*...*/}
As an example, we can have a module with an internal negative backedge of -3, which itself contains some state that the backedge can originate from. The module wraps the backedge this way, and proves all of the safety requirements that come with using it. The user then is free to connect the output of this module combinatorially with the input, and with at most 3 cycles of latency.

As a more concrete example, consider the write side of a FIFO.

Latency specification
Specifying latencies on every single input and output is a bit cumbersome, so we wish to infer latencies as much as possible. Sometims however specific constructions with indeterminable latencies require the user to explicitly specify the latencies. We will explore such cases in later chapters.
When the user specifies latencies on multiple nodes, they are in effect stating that they know what the exact latencies between the given nodes are. Theorethically we should include this into the algorithm as extra edges between each pair of nodes a and b, of latency lb-la and -(lb-la) backwards. This fixes the latency differential to be as the user specifies it. In practice in the Latency Counting Algorithm, we don't actually do this in this way, but instead handle specified latencies in a dedicated part of the algorithm, to provide the user with more readable error messages. In any case, the latencies assigned by the algorithm should be equivalent to doing it with the extra edges.
If the user provides not a single latency annotation, then we allow the compiler to set an arbitrary node's latency to 0, as a seed for the algorithm. Because input and output nodes have to be fully constrained, the compiler picks one of these if possible.
Requirements for the latency counting system
- Addition or Removal of any latency registers that do not violate a constraint must not affect the operation of the design.
- Feedback loops containing only latency are considered combinatorial feedback loops, and are therefore forbidden. Feedback loops must therefore have at least one state register in them.
- When the user specifies a latency of 1 somewhere using the
regkeyword, this instructs the compiler that the minimum latency between these points is now 1. The compiler is allowed to insert additional latency registers between any two nodes as it sees fit. - State registers to not impact the latency counting. They count as 0 latency.
- Any loop (which must contain at least one state register) must have a roundtrip latency ≤ 0. Negative values are permitted, and are simply attributed to the use of negative back edges.
- Specified latencies must be matched exactly.
Extra requirements to allow latency inference
- The latency between input and output nodes that have a combinatorial connection must be minimal. In other words, if an output
o'lois reachable from an inputi'liby only following forward dependencies, then|lo|-|li|is exactly the latency of the longest path between them. - Nodes that are not an input or output, don't have a latency specified, and have multiple options for their latency are set to the earliest possible latency.
Latency Counting Graph Algorithm
We are given a directed graph of all wires and how they combinatorially depend on each other. Each edge can have a number of latency registers placed on it.
Example:
// timeline is omitted here, not important
module Accumulator {
interface Accumulator : int term, bool done -> int total_out
state int total
int new_total = total + term
if done {
reg total_out = new_total
total = 0
} else {
total = new_total
}
}
Which results in the following graph:

Nodes are coloured by role. Blue nodes are inputs, green nodes are outputs, orange nodes are state registers, and white nodes are combinatorial.
On the edges are noted the minimum latency offsets in black. These are given. The goal of the algorithm is to compute a set of 'absolute latencies', which are all relative to an arbitrary node. These are given with the red nodes on the picture. Because these absolute latencies are relative to an arbitrary reference point, we accept any constant shift applied to all absolute latencies as equivalent.
Non Determinable inference of Input and Output absolute latencies
Sadly, while it appears reasonable to think it's possible to assign a determinable latency. Observe this contrived example:
module NonDeterminableLatency {
interface NonDeterminableLatency : int a, int b -> int x, int y
reg int a_d = a
int t = a_d + b
reg reg reg int a_dd = a
reg int t_d = t
x = t_d + a_dd
y = t
}
Simplified latency graph:

The issue starts when the inputs and outputs don't have predefined absolute latency. We are tempted to add maximization and minimization to the input and output absolute latencies, to force the module's latency span to be as compact as possible, and therefore maximize how free the user of this module is in using it. But sadly, we cannot make a uniquely determinable latency assignment for our inputs and outputs, as in this example b and y press against each other, permitting two possible implementations.
One may think the solution would simply be to prefer inputs over outputs or something, just to get a unique latency assignment. Just move b to be the earliest of the available latencies, but even in this case, if we instead looked at the possibilities of a, and fixed b, we would again make b later by making a earlier. And since there's no way to distinguish meaningfully between inputs, there's no uniquely determinable solution either.
To this problem I only really see three options:
- Still perform full latency computation when compiling each module separately. In the case of non-determinable latency assignment, reject the code and require the programmer to add explicit latency annotations. The benefit is better encapsulation, the programmer requires only the module itself to know what latencies are. The downside is of course less flexible modules. Though is this flexibility really needed?
Infer absolute latencies on the inputs and outputs of submodules using templates which can be inferred. This would be really handy to allow latency information to flow back into the templating system, thus allowing a FIFO that alters its almostFull threshold based on its input latency. Of course, this makes absolute latency information flow from top-down instead of bottom up, so now getting the latency information back from the module would be impossible. The issue is that templates can't be instantiated partially. Either the submodule takes all of its port latencies from the calling module, or it determines its latencies itselfPerform latency computation at integration level, we don't define the absolute latencies on the ports of a module, unless the programmer explicitly does so. For simlpicity, this requires that every single module instantiation now compiles to its own Verilog module though, which is less than ideal for debugging
Simply solve the above module by explicitly specifying latencies to the two inputs:
module LatencySpecified {
interface LatencySpecified : int a'0, int b'1 -> int x, int y
reg int a_d = a
int t = a_d + b
reg reg reg int a_dd = a
reg int t_d = t
x = t_d + a_dd
y = t
}
Latency Graph Cycles are the key
So assigning absolute latencies is difficult, and no good solution can be found in isolated cases. Perhaps another approach would work better.
In essense, what are the reasons for which we want to count out latencies? The initial one of course was keeping signals in sync. In the vast majority of cases when you pipeline a design, you don't want to cross signals from different time steps. But of course, after pipelining a design, you need to deal with the effect that this module now takes several cycles, and has a certain capacity to store in progress data.
Maybe instead of trying to infer the latencies from the pipeline with inputs and outputs, we focussed our attention purely on the cycles. These are already nice and constrained.
Should Compound Types' latency be kept in sync?
Arrays, structs, tuples, etc. Should the absolute latencies of these be kept in sync? On the one hand, it's easier on the programmer if they do stay in sync. It's easier to reason about. A problem is though, that strictly keeping all latencies of an array in sync could introduce unnecessary dependencies, and therefore make the pipeline deeper than it needed to be. Also, if we forcibly keep array and struct elements in sync, then we can't express certain generic construct, such as a latency shift register, or allowing us to pipeline a sequence of similar steps where intermediary results are all stored in the same array.
If you go all the way to the opposite end of the spectrum however, splitting up every struct, every array, and every tuple into their component wires, then the development experience suffers. For Arrays or structs with differing latencies the compiler can't give nice diagnostics. Also from a simulation perspective, simulators know the concepts of arrays and structs. Should SUS outputs only be simulable on a wire-by-wire basis? Or should we keep the structures intact but have internally different latencies? None of these options are really appealing.
Of course, we could mostly mitigate this by re-merging structs and arrays that happen to all have the same latency. But then again, it feels like it would be brittle and cause unexpected errors for the programmer.
In the end, I think that having the programmer explicitly state when to split a latency is best. And we do this with the 'split latency specifier. This explicitly splits the underlying wire into separate 'real' wires. This allows the programmer to make the tradeoff, for explicit latency flexibility, and accepting the cost that this structure will be less nice in the resulting verilog.
The SUS Standard Library
By making cycle-latency mostly transparent to the programmer, we enable the use of more generic building blocks. These should be grouped into a standard library built specifically for the language.
Common interfaces
The Standard Library should provide standardized names for common interface types, such as memory read and write ports and AXI ports. This helps standardise the interfaces of distinct libraries, allowing for easier integration.
Memory blocks and FIFOs
Configurable Memory primitives and FIFOs should certainly be part of the standard library. These are so fundamental to any hardware design, and appear to be uniquitous across FPGA vendors. These Memory primitives should however not be fully fixed. Attributes such as read latency and read-write conflict resolution vary substantially between vendors, so this should be left up to the target platform. However of course it should always be possible to properly fix these values in situations where the programmer needs them. Such as when one needs a 0-cycle memory read, even if that would mean it would reach terrible timing, or not synthesize at all on some platforms.
This is also the reason why I believe the 'inference' doctrine of defining memory blocks is fundamentally flawed. An inference implementation will always make implicit assumptions about the read latency and read-write conflict, meaning the code isn't properly portable across devices.
Multi-Clock Memories and FIFOs
It is still up for debate whether multi-clock variants should be implicit from the use, or explicit different types. There are arguments to be made for both approaches. Certainly this gets blurry when making the distinction between synchronous and asynchronous clocks. In any case, multi-clock modules should be available in the Standard Library in some form.
Shift registers, skid buffers, packers, unpackers
These are quite natural utilities that any project could use.
Clock Domain Crossings
Clock Domain Crossings are a famously difficult problem in hardware design, and are a source of many sporadic and difficult to find bugs. The way one does a clock domain crossing also very much depends on the circumstances. Thus again, no all-encompassing generic solution can really be given. However, various common CDC implementations should be offered in the Standard Library, which can then prove connecting code safe using rythms.
Implementation of the Standard Library
Generally, a generic implementation can be given for all Standard Library types. But these won't work well on most platforms. For each platform, there should be platform-specific implementations of each of these.
Standard Library extensions
In fields like HPC, certain interfaces are ubiquitous, such as DDR memory interfaces, HBM, PCIE and Ethernet. In general these don't fit in the standard library itself, as these features are not available on the majority of platforms, but instead could be offered as separate libraries. These could (like with the Standard Library) provide differing implementations over a generic interface, to again enable more cross-platform code.
Optimization
One important observation I recently made was on Optimization. I had been quite proud of my unusual stance on "Optimization is a Non-Goal". But as I add more and more abstractions to the language, I come around to a different conclusion. Being a hardware designer in the lowest abstraction layer - Verilog, I believed that hardware itself was fundamentally unoptimizable when written out in this lowest abstraction layer, because any optimization the compiler could do could go against the intention of the programmer, undoing for example place-and-route considerations the programmer had made. As I introduced new abstractions however, I kept bumping into the problem of "what if I don't need this abstraction?".
Making the abstractions always optional seemed to run counter to the safety promises I wanted to make, instead what would we ideal was if the programmer can specify their interface within the bounds of the abstraction, and somehow prove that the compiler will recognise the situation and remove the abstraction's overhead. In essense, this is what it means to do optimization.
This more nuanced view is summarized as follows:
Optimization should be a goal insofar as it is the un-doing of abstractions.
Likewise, abstractions are only permissible if there is some all-encompassing optimization the compiler can perform to undo the abstraction if needed.
I still believe hardware is still broadly unoptimizeable. In contrast to software design, where the primary optimization target is Speed, in hardware there are multiple targets that are mutually at odds with each other. Clock speed, Cycle latency, logic, memory and DLS utilization, and routing congestion. No 'optimal' HW solution exists, and so it is up to the programmer to make this tradeoff.
This is why I consider HLS to be misguided in their "Just write it as software code and we'll do the optimization for you" approach.
On State
For latency see latency
State goes hand-in-hand with the flow descriptors on the ports of modules. Without state all a module could represent is a simple flow-through pipeline.
But once we introduce state, suddenly modules can have a wide range of output patterns and required input patterns. A simple example would be a data packer or unpacker. An unpacker receives a data packet, and outputs its contents in parts over the next N cycles. How should this unpacker behave when it receives another data packet before it finishes? It can either discard what it's currently working on, or discard the incoming data. Either way, data is lost. So the packer's interface must prohibit incoming data for N-1 cycles after a valid packet.
The language we choose for the interfaces is that of the regex. This is a natural choice, since in effect any module the user writes is a state machine, and regexes can be converted to state machines. State machines have a nice property, that operators for working with state machines are polynomial and easy to understand.
Structural and Data State
We have to check the state machine that is each module against the state machines of the modules it uses of course. Sadly, this checking can only really be done in a generic way by generating the full module state machine, and checking its behavior against the state machine from its dependents' interfaces, as well as its own.
Generating the whole state machine is a combinatorial endeavour however, and a too wide state vector quickly leads to an unmanageable number of states. This encourages us to differentiate between two types of state. Structural State (namely state whose instances are incorporated into the module STM), and Data State, which (aside from its validity) is not. We wouldn't care about every possible bitpattern of a floating point number we happened to include in our state right?
Examples
Summing module
timeline (X, false -> /)* .. (X, true -> T)
module Accumulator {
interface Accumulator : int term, bool done -> int total
state int tot := 0 // Initial value, not a real assignment
int new_tot = tot + term
if done {
total = new_tot
tot = 0
finish // packet is hereby finished.
} else {
tot = new_tot
}
}
In this case the compiler would generate a state machine with two states. One state for when the module is active, and one is generated implicitly for the inactive case. The regex is mapped to a 3-state state machine. Represented below:
- A:
inactive - B:
(X, false - /) - C:
(X, true - T)
The regex produces the following NFA: (-> is a consuming transition, => is not)
- A -> A when !valid
- A => B when valid
- B -> B when !done
- B => C when done
- C -> A
Compiled to a DFA this gives:
- A -> A when !valid
- A -> B when valid & !done
- A -> C when valid & done
- B -> B when !done
- B -> C when done
- C -> A when !valid
- C -> B when valid & !done
- C -> C when valid & done
The code's state machine must be proven equivalent to the regex state machine. This is done by simulating the code STM based on the regex. The code must properly request inputs at regex states where inputs are provided, and may not when not. It's inputs must be valid for any path in the regex STM, while it's outputs must conform to some path of the regex.
Any module working on finite packet sizes must also specify the finish keyword when the module is finished sending a packet.
At this point the initial conditions must be reestablished explicitly. After this, the module goes back into the inactive state.
In this example, the code simulation starts right in its initial state. Then the different paths of the regex STM are all simulated. For the case of infinite loops, we save any distinct (regex, code-STM) pair we come across, and skip combinations we've already come across.
Since in this example the only active state for the code corresponds to both active states of the regex, the code must abide by the constraints of both regex paths. And it does, in the case done == false the module may not output total Likewise, in the case done == true, the module must output total. And in the case of done == true, the code has to go back to the initial state through the finish keyword.
The caller is then responsible for providing a stream of the form of the regex.
Unpacker
The previous example was quite simple though, with the code's active state machine containing only one state. In this example we explore a module that does have structural state.
timeline (X -> X) .. (/ -> X) .. (/ -> X) .. (/ -> X)
module Unpack4<T> {
interface Unpack4 : T[4] packed -> T out_stream
state int st := 0 // Initial value, not a real assignment
state T[3] stored_packed
if st == 0 {
out_stream = packed[0]
stored_packed[0] = packed[1] // Shorthand notation is possible here "stored_packed[0:2] = packed[1:3]"
stored_packed[1] = packed[2]
stored_packed[2] = packed[3]
st = 1
} else if st == 1 {
out_stream = stored_packed[0]
st = 2
} else if st == 2 {
out_stream = stored_packed[1]
st = 3
} else if st == 3 {
out_stream = stored_packed[2]
st = 0
finish // packet is hereby finished.
}
}
In this case, the regex has 4 states, but we don't know what number of states the code has. One could bound the integer st of course, and for the number of states multiply together the counts of all structural state objects we find. But we don't need to. We can simply simulate the code, only explicitly saving the structural state fields.
In this case, we know the starting value of st, and we just need to simulate the hardware with this. So in the first cycle, we are obligated to read from packed, and write to out_stream. Following the code that is the case, as we execute the first branch: st == 0. We know the next state st = 1, so we continue going along. This continues for the remaining states of the regex, ending at st == 3 where we also call finish.
On Registers
State vs Latency
In my experience, the use of registers usually boils down to two use cases:
- Representing a current working state, which gets updated across clock cycles
- Improving timing closure by introducing registers on tight paths.
While this distinction exists in the programmer's mind, it isn't in the vocabulary of common compilers. Verilog and VHDL just call both 'reg' (And non-registers too, but that's another can of worms.)
Philosophically, the difference is quite important though. Registers that are part of the state are critical, and they directly direct the functioning of the device. While latency registers should not affect the functioning of the design at all, aside from trivially affecting the latency of the whole design. Some would argue that worrying about latency registers is a solved problem, with retiming tools that can automatically migrate latency registers across a design to place them wherever more timing slack is required. In practice though, this capability is limited, usually by explicitly marking specific paths as latency insensitive, or in a limited way by synthesizing a block of registers somewhere, which should then be migrated across the design. Still, this practice is always limited by the first design register it comes across along the path. Explicitly differentiating between state and latency registers could make this automatic retiming much more powerful.
While indeed generally latency can't affect the actual operation of the device, it can be disallowed in certain circumstances. Certain paths are latency sensitive, and would no longer produce correct results if latency were introduced. A trivial example is any kind of feedback loop. In this case, no latency can be introduced within the feedback loop itself, as the result for the current feedback loop cycle wouldn't arrive in time. In this case the latency should either be forbidden, or reincorporated in a different way, such as interpreting the state loop as a C-Slowed state loop.
On State
See state
On Latency
See latency
The Trouble with Parsing Templates
Templates in the modern style of C++ or Java are incredibly hard to parse, and seemingly manage to conflict with just about every other syntax in common use. They can occur in many circumstances. Most commonly in types, but also in function calls and constants. Their ubiquity compounds the issues described below.
void myFunc() {
vector<int> myVec;
}
All languages that choose to adopt this standard employ limitations around their use. In Java it's not possible to pass values as template arguments, in C++ often the template keyword must be inserted for the parser to understand.
Take the fully ambiguous case of this function call:
myFunc<beep>(3)
This can be parsed in two ways:
- The way we as the programmer intend, IE it to be a template instantiation
- Two comparison operators with a value between parentheses:
(myfunc<beep) > (3)
This is a proper grammatical ambiguity.
Template troubles for SUS
In SUS there's quite a few things that come together that make this notation of templates difficult. For starters, SUS also has the < > comparison operators, which provides an immediate conflict, just like in the above example.
Another less well known conflict from this notation comes from the commas. Take calling:
myFunc(choice<3, 6>(5), x, y, z);
If the parser interprets the < as a comparison, then the commas separate function arguments, but if it were to interpret them as a template then the first comma separates template arguments.
What's more, SUS has a few extra notations that also conflict with this idea, namely multiple value declarations, which are used for functions that return multiple values.
To illustrate:
int b;
int[5] c;
int a, b, c[0], myType<int, bool> d = myFuncReturningFourResults();
Where the intent is to assign to a newly declared a, an existing variable b, indexing into array c, and a new variable d.
This notation combines declarations with assignable expressions.
The issue is that if the compiler can accept both declarations and arbitrary expressions, then there's two perfectly valid parses for d. Either the one we intend, or it becomes two expressions myType<int and bool> d.
While it may seem a bit dumb to assign to the output of a comparison operator to the parser it's all _expression.
Solutions
There's two solution archetypes I see: The Rust solution, and the Verilog solution. I've chosen a mix of the two.
Rust
In so-called "type contexts", where the only this that's allowed to be written is a type, types are simple: Option<i32>, Result<Vec<i32>, String>, etc.
Rust solves it with adding ::< in cases where it would otherwise be a parsing ambiguity, like my_func::<3>(5). This disambiguates it from the comparison operators. But here still, a comparison expression inside the arguments list breaks it again: my_func::<3 > 1>.
Luckily, Rust sidesteps this by banning expressions in template all-together, as allowing that itself would also introduce a whole lot of dependent types mess that turns pre-monomorphization into an undecidable problem.
Verilog
The Verilog solution is to simply move away from the angle bracket notation, and use a different one that doesn't conflict so heavily. In verilog's case, that's the #(.varA(x), .varB(y), ...) notation. The advantage here is explicitness, which is important in HW design, since otherwise you'd be instantiating modules like FIFO #(32, 6, 2) and you wouldn't know what the numbers mean.
This is not the only way to use templates in Verilog though, but in my opinion the defparam syntax is so verbose I'll leave it out of consideration.
SUS
In Hardware Design, as opposed to software design, the vast majority of template instantiations do not depend on types, but rather on values. While software is full of things like Result<Vec<i32>, ErrorObject>, in hardware the sizes and parameters are numbers.
The typical example is instantiating a library Memory block: Memory #(int DATA_WIDTH, int DEPTH, bool USE_OUTPUT_PIPELINE_STAGE, bool READ_PIPELINE_STAGE, etc). Using an unambiguous syntax may just be the solution here.
And yes, while Verilog's solution may not be familiar to software programmers, hardware designers are used to it.
I will, however, make one change to Verilog's notation. Taking inspiration from Rust, and in accordance with Hardware programmers' desire for explicitness, I'll change the template instantiation syntax to use named arguments with short form syntax:
module FIFO#(T, int SIZE, int LATENCY) {...}
module use_FIFO {
gen int LATENCY = 3
FIFO#(SIZE: 32, LATENCY, type T: int[3]) myFIFO
myFIFO.push(...)
}
So in this example, SIZE is set to the result of the expression 32, LATENCY happens to be named identically to the variable we assign to it, thus Rust's short form. And the type we pass in requires a special type keyword so the parser can distinguish it. Perhaps that could still be changed, since grammatically types appear to be a proper subset of expressions, but it also seems dangerous from an IDE perspective, as now it's not clear from the parse tree what it's supposed to be. Regardless, in many of those cases, types are easier to infer than values so the type fallback syntax should be a rare occurence.
Implementation Tensions
HW Design wants as much templating as possible --- Turing-Complete code generation can't be generically checked
Solutions
- Don't analyze Templated Code before instantiation (C++ way)
- Default Args required, do user-facing compile based on these.
- Limit Code Generation to a limited subset that can be analyzed generically. (Lot of work, will eliminate otherwise valid code)
Compilation Ordering: Code Generation --- Flow Analysis --- Latency Counting
Most of the time, Latency Counting is dependent on Template Instantiation. For example, a larger Memory may incur more latency overhead for reads and writes.
On the other hand, one could want a measured latency count to be usable at compile time, to generate hardware that can specifically deal with this latency. For example, a FIFO's almostFull threshold.
Another important case: Automatic Generation of compact latency using BRAM shift registers. The compiler could instantiate a user-provided module with as template argument the latency between the bridging wires, but the module may then add vary in its latency depending on the memory block size, requiring the compiler to again fiddle with the template argument.
Solutions
- Always compile in order Template Instantiation -> Flow Analysis & Latency Counting. Explicitly state template args. Add asserts for latencies that are too high and reject designs that violate this.
- For each nested module separately, perform Template Instantiation & Latency Counting first, and allow use of measured latency of higher modules
- Add latency template arguments, allowing higher modules to set the latency of lower modules. Reject lower modules that violate this latency.
To use, or not to use Tree Sitter
Should the SUS compiler use tree-sitter as its parser? Of all the parsers I've looked at, tree sitter is the most promising, combining both strong error tolerance with incredibly efficient parser generation. But switching may be a big task.
Arguments
For custom parser
- Possibly easier to report errors, even though tree sitter is error tolerant, it can't produce diagnostics such as "Expected token such and such here"
- Already have a big parser built out
- Custom parser produces nicely typed syntax tree
Against custom parser
- Probably I'm not skilled enough to build a proper recursive descent parser for more complex cases, like templates
- Still lots of work, also possibility of many panics in custom parser, tree sitter is quite reliable error wise
For Tree Sitter
- Really efficient parser, using a direct state machine is something I could never beat myself.
- Incremental updates. Speed of development is a big selling point for SUS
- Actually can parse the stuff I need to parse
- More reliable error recovery.
Against Tree Sitter
- Cumbersome interface, lots of Node::kind calls etc
- Don't know when tree sitter produces ERROR nodes and when not, when can I assume I can
unwrap()stuff? - Don't like deeply adhering myself to a parser library, because it makes future changes more difficult, like with Ariadne
- People online say it's unsuitable for compiler frontend development.
Verdict
Having gone through the effort of switching to tree-sitter, I can say I'm very content with the change.
I'll now again go through the advantages and disadvantages I listed above, and show new perspectives.
Post-use For Tree Sitter
- Tree-sitter has proven an incredibly performant parser
- The incremental updates are still a big selling point for the future
- While I have found tree-sitter poorly documented, and difficult to debug, it has managed the things I needed it for
- Error recovery
Post-use Against Tree Sitter
- The interface turned out far nicer than expected, once I built a wrapper for it. Also some proc-macros to request the node kinds at compile time was a godsent.
- So ERROR node production is still a mystery in many cases, but with a decently unambiguous grammar where it fails to parse is pretty much always obvious
- Welp, I've adhered myself now, and I'm happy I did.
- I've placed a comment on this thread explaining my experience.
Product Types
Product types or structs are quite natural to express in hardware and should be supported by the language. A product type is represented as a bundle of the field data lines that together form the whole struct.
Sum Types
Sum types, are the natural companion of Product Types. Though they are far less commonly supported in Software Languages, they have been gaining ground in recent years due to the popularity of the Rust Language. For software compilers, their implementation is quite natural. Since we only ever use one variant of a sum type at a time, we can share the memory that each of them would take up. This has many benefits: reduced struct size, possibility for shared field access optimization, and no real downsides.
The same however, cannot be said for hardware design. In hardware design, there are two main ways one could implement a sum type. Either sharing the wires for the variants, or having each variant have their own separate set. Which implemenation is most efficient depends on how the sum type is used. In the case of sharing the wires, we incur the cost of the multiplexers to put the signals on the same wire, as well as the additional routing and timing cross dependencies it introduces between the variants. On the other hand, in the case of separating out the variants into their own wires does not incur this cost, but storing and moving the sum type around takes far more wires and registers.
No natural implementation choice exists for Sum Types, and thus they shouldn't be supported at the language level.
One exception however, is quite natural in hardware, and that is the Maybe (or Option) type. Sum types in general actually fit nicely with the flow descriptors system, where the developer can specify which level of wire sharing they want, and which ports should describe separate variants.
Finally, there should be a type-safe implementation for a full wire-sharing sum type. That should be supported by the standard library, using something like a Union type, for those cases where the reduction in bus width is worth the additional multiplexers and routing constraints.
Enums
Enums are lovely. It's important that the programmer can specify what the exact representation is, such that the compiler can optimize their use. Be it as a one-hot vector, binary encoding, or a combination of the two.
Core Philosophy
SUS is meant to be a direct competitor to Synthesizeable Verilog and VHDL. Its main goal is to be an intuitive and thin syntax for building netlists, such that traditional synthesis tools can still be used to analyze the resulting hardware. SUS shall impose no paradigm on the hardware designer, such as requiring specific communication protocols or iteration constructs. In other words, SUS is not there to abstract away complexity, but rather to make the inherent complexity of hardware design more manageable.
The one restriction SUS does impose over Verilog and VHDL is that it requires the hardware to be synchronous over one or more clocks. Asynchronous hardware is therefore unrepresentable making SUS less suitable for ASIC development.
There are three main features that set SUS apart from the rest:
- Generative Variables and Types can be freely combined. Any "Dependent Types" headaches that are caused by this are sidestepped by doing the main type checking after instantiation.
- Easy Pipelining through an orthogonal language construct called "Latency Counting". 'Orthogonal' means that adding pipeline registers does not interfere with other language features such as generative or conditional code.
- Separation of pipelines with interfaces. This keeps the user from accidentally crossing signals that have no logical relationship. At this level Clock Domain Crossings are implemented.
Finally, an important consideration of SUS is the user interface. SUS comes with a VSCode IDE plugin that allows the copiler to be used fully in-IDE. Compiling, typechecking and instantiation is done as the user writes code, leading to a very tight development feedback loop.
What SUS gives you
- A direct 1-to-1 mapping from code to netlist
- Hardware domain separation with explicit crossing primitives
- A built-in syntax for pipelining that does not impose structural constraints
- In-IDE compilation errors & warnings
- Metaprogramming for hardware generation
Planned
- Type safety with Bounded Integers
- Multi-Clock modules
- Formal Verification Integration
- Syntactic sugar for common constructs like valid signals, resets and submodule communication
- Moving some1 timing constraints to the source file
Some timing constraints affect the cycle-by-cycle functioning of the design, such as the relative speeds of synchronous clocks and False/Multi-Cycle Path constraints. Because they affect the cycle-wise behaviour of the design, they should be provided as part of the language and incorporated in simulation. Of course, timing constraints like real clock speeds, edge patterns and external component timings still rightfully belong in the Timing Constraints file. It should not be possible to express SUS code that behaves differently between Simulation and Synthesis.
What SUS does not do
- Provide abstractions for handshake protocols (Like AXI)
- Runtime Iteration Constructs
- Automatic Pipelining & Retiming
Of course, while the language does not support such protocols directly in the syntax, as this would put unneccesary extra constraints on the output hardware, modules for handling them will be provided in the standard library.
SUS Code Examples

Main Features through examples
Pipelining through Latency Counting
module pow17 {
interface pow17 : int i -> int o
int i2 = i * i
reg int i4 = i2 * i2
int i8 = i4 * i4
reg int i16 = i8 * i8
o = i16 * i
}

FIZZ-BUZZ Lookup Table using Generative Code
module fizz_buzz_gen {
interface fizz_buzz_gen : int v -> int fb
gen int FIZZ = 15
gen int BUZZ = 11
gen int FIZZ_BUZZ = 1511
gen int TABLE_SIZE = 256
gen int[TABLE_SIZE] lut
for int i in 0..TABLE_SIZE {
gen bool fizz = i % 3 == 0
gen bool buzz = i % 5 == 0
gen int tbl_fb
if fizz & buzz {
tbl_fb = FIZZ_BUZZ
} else if fizz {
tbl_fb = FIZZ
} else if buzz {
tbl_fb = BUZZ
} else {
tbl_fb = i
}
lut[i] = tbl_fb
}
fb = lut[v]
}
In the end, the generative code is executed and all that results is a lookup table.
(Clock-) Domains for separating out logically distinct pipelines
For this feature to be useable you really must use the LSP. The semantic analysis of the compiler gives important visual feedback while programming that makes this much easier to understand.
In this example, we create a memory block with a read port and a write port. This module has two domains: The read interface domain and write interface domain. Every wire in the design is part of one of these domains (or an anonymous domain if it's not connected to either interface). Signals are not allowed to cross from one domain to another unless explicitly passed through a domain crossing primitive.
